Chapter 1 Overview of common visualizations and how to read them
This book will cover how to create a variety of visualizations using R. One of the first things you should do to improve your skills creating visualizations is to become familiar with the kinds of visualizations that are possible and the different features of each.
Effective visualization design relies on a solid understanding of how data properties, visualization types, and audience characteristics interact to help people make sense of a visualization. In this chapter, we’ll look at a series of common visualization types, and we’ll break down how each is meant to be read. Understanding these basic visualization types will create a solid foundation for communicating your data science work to a broad audience.
1.1 Visualization components
As we discuss different visualizations, we will also be talking about different components within the visualizations. In figure 1.1 below, the major components of the visualization are labeled: the main title, the subtitle, the x axis title, the y axis title, the panel, the horizontal and vertical gridlines, and the axis labels and tick marks for both axes. Almost all of the visualizations we cover in this book will use these basic components.
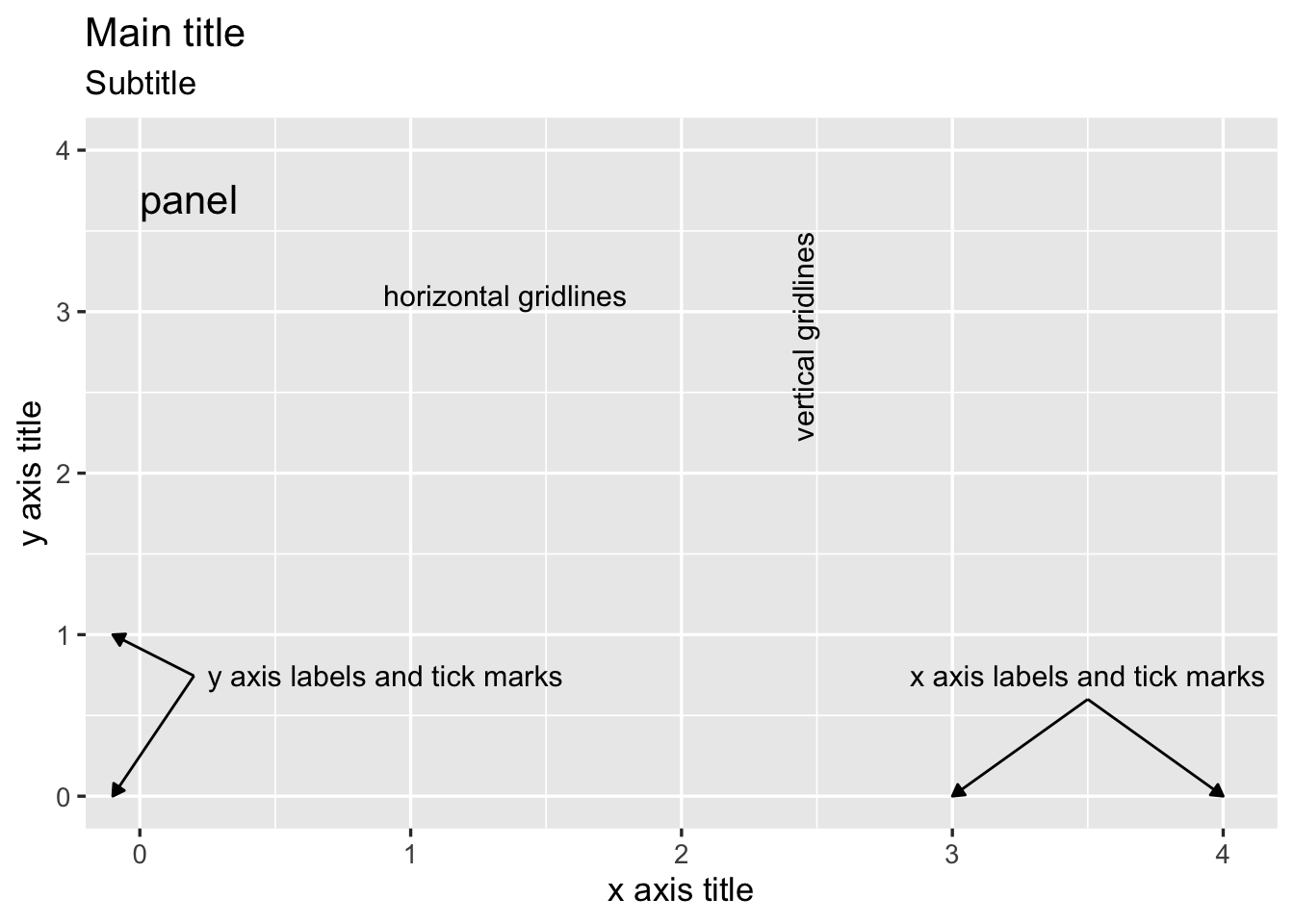
FIGURE 1.1: Visualization components, labeled.
In this set of basic visualization components, we see two components labeled as an axis. These axes are called the x and y axes, and they always appear in these positions: the x axis always goes left to right, and the y axis always goes up and down.
1.2 Bar Chart
The bar chart is possibly the most common type of visualization. In this type of visualization, the basic shape being used to represent data values is a rectangle. In a traditional bar chart, each rectangle (or bar) has exactly the same width, and the height of the bar is representative of some data value. To create a simple bar chart, the data set should have one column that contains textual (or categorical) data and one column that contains numerical data. A common way to create these two columns is to start with one categorical data column and count the number of records for each category to create the numerical column.
In figure 1.2 part A, the categorical variable is displayed on the x axis and the numerical variable is displayed on the y axis. This results in a classic style of bar chart where each bar has the same width and the heights are proportionate to a data value. Each bar has a starting value of zero on the y axis. Each bar travels upward from zero and stops at the correct data value.
When reading this visualization, we are comparing the lengths of bars in order to understand patterns within the numerical data values from our data set. The power of the bar chart lies in how precisely we can detect differences in the end points of the bars. This is something that people naturally do quite well when all of the bars start at the same lowest point, or baseline.
Bar charts are especially effective if the bars that have small differences in lengths appear close to each other. In the above chart, this is accomplished by arranging the bars so they appear with the highest data values on the left and the lowest data values on the right.
In figure 1.2 part B, the data values include both positive and negative values. For data values that are negative, the bar travels downward from zero and stops at the correct data value. The x axis title and labels appear at the bottom of the panel, below the lowest data values.
For stylistic reasons, bar charts may also appear with the bars oriented horizontally instead of vertically (figure 1.2 part C). In that case, each bar will have the same height, and the widths of the bars will vary based on the data values. The text (or categorical) axis will then be the y axis, and the numerical axis will be the x axis.
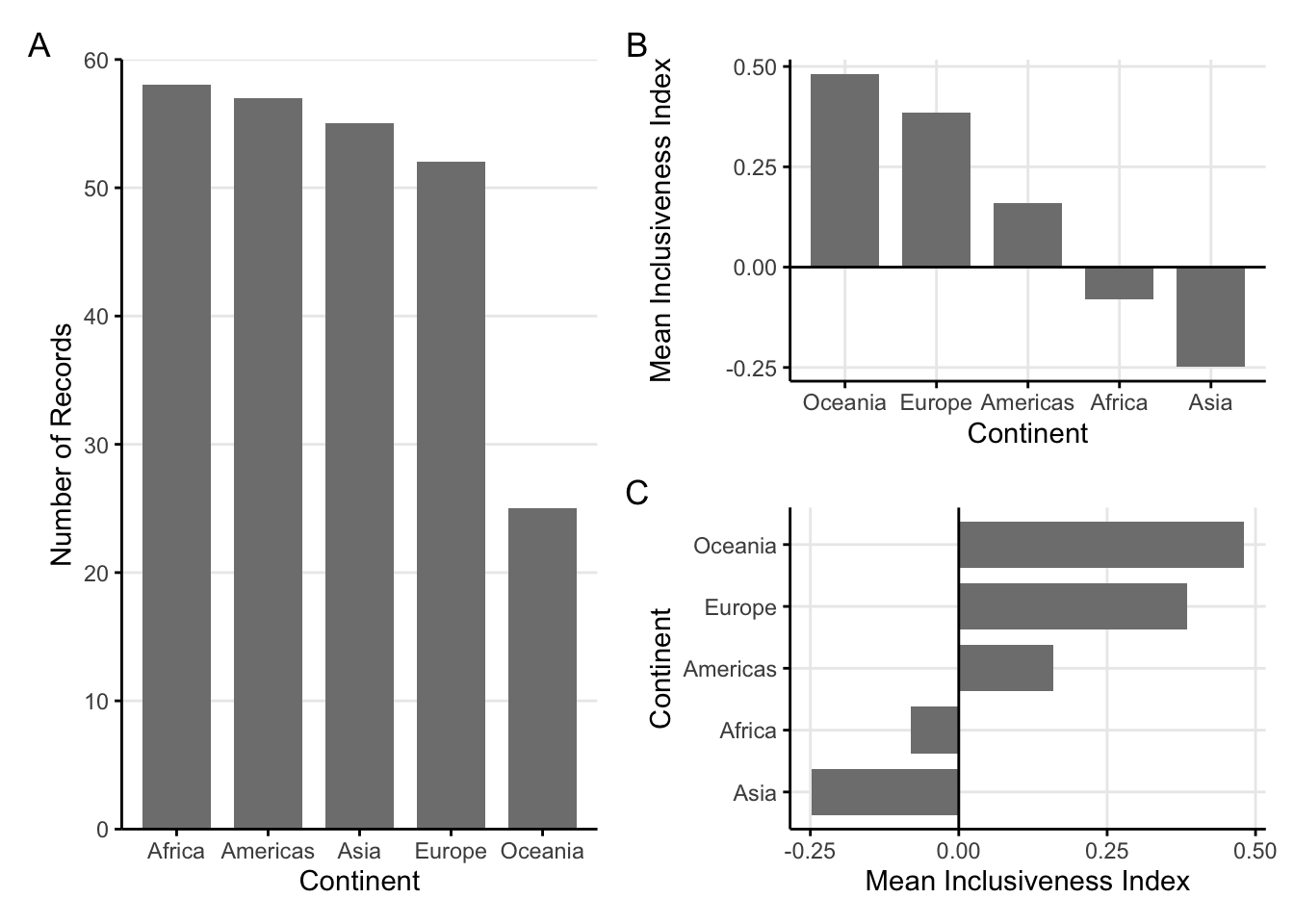
FIGURE 1.2: Three sample bar charts. A: A sample bar chart with vertical bars. B: A sample bar chart with both positive and negative values. C: A sample bar chart, with the bars oriented horizonally.
1.2.1 Variations
Sometimes, we may have data that would work well for a bar chart, but we may want to explore a variation that would change the basic shape of the chart. There is one main variation of a bar chart: the lollipop chart.
1.2.1.1 Lollipop plot
The lollipop plot is a simple variation on the bar chart. In a lollipop plot (figure 1.3), the bars are replace by a long line with a circle at the end, creating something that looks like a lollipop. Apart from the different shapes used, the lollipop plotworks just like a bar chart. The circles draw attention to the data value, but the lines extending to the axis reinforce the length comparisons.
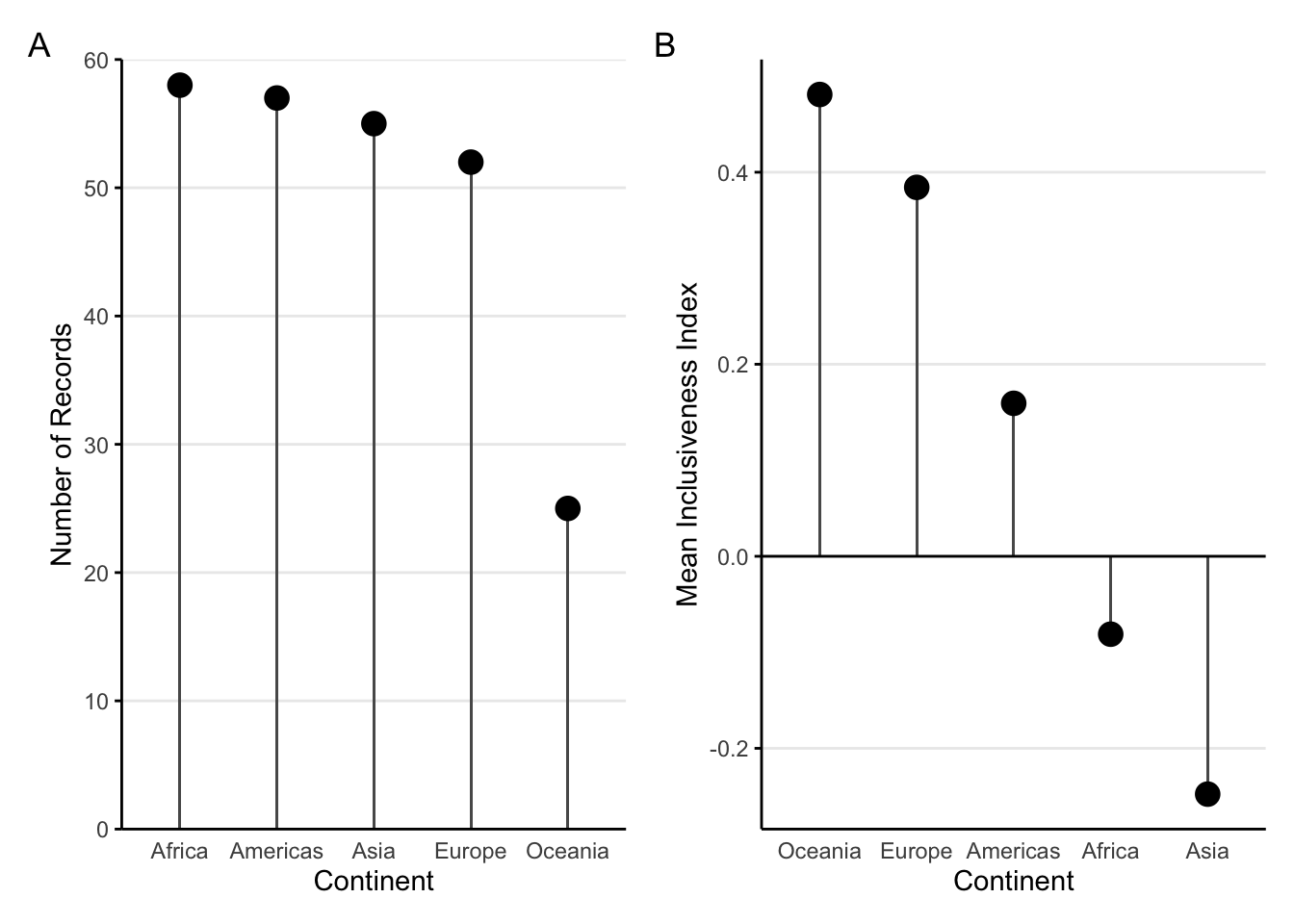
FIGURE 1.3: Two sample lollipop plots. A: A sample lollipop plot. B: A sample lollipop plot with both positive and negative values.
1.2.2 Add a variable: Bar charts with color
A simple bar chart includes one categorical variable and one numerical variable. Sometimes, however, it is useful to explore the patterns in relation to a second categorical variable. Adding another categorical variable to a bar chart usually means using color to represent the extra variable.
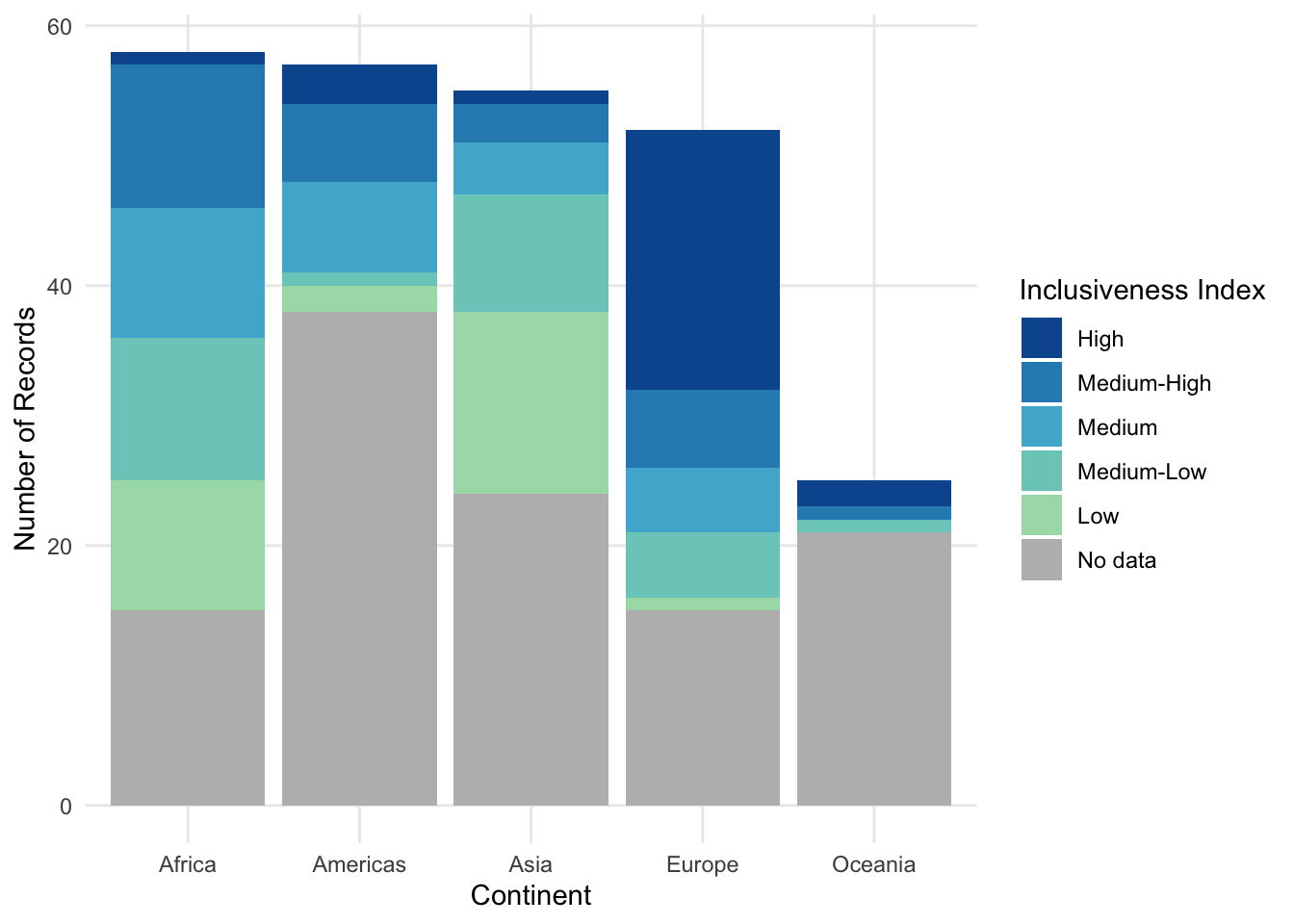
With a stacked bar chart, the additional variable is used to segment the bars into separate, colored regions. In figure 1.4 part A, the bar for each continent is subdivided into groups of countries based on their values for Inclusive Index.
With this stacked bar chart, you can still see the total number of records for each Continent, but what happens when you try to compare the different segments inside the bar chart? Starting at the bottom, it seems to work out okay. All of the bars for the “No data” category start at the same baseline (the x axis), and we can read these segments like a normal bar chart. But what happens with the “Low” segments right above them? And the “Medium-Low” segments above those? Every time we have a group of segments that aren’t lined up with each other, we have to try to guess how tall the bar is in comparison to the other bars in the group. The farther apart the segments are, the harder it is to make that comparison.
Another variation of the stacked bar chart is the “filled” stacked bar chart (figure 1.4 part B). Instead of using the raw counts to determine the lengths of the bars, in the filled stacked bar chart, the full bars are all stretched to have the same height, and each segment becomes the percentage of the records in each bar. (Notice how the y axis changes from “Number” to “Percentage.”) This is useful if the percentagesmatter more than the raw counts, but it doesn’t fix any of the concerns with comparing different segments without a common baseline.
An alternative to the stacked bar chart is called the grouped bar chart (figure 1.4 part C). In the grouped bar chart, every segment starts from the x axis. Each continent forms a group of bars, and each option of the Inclusiveness Index is a separate bar. While it’s easier to see the length of each bar, it can now be difficult to look at the trend within a single color group because the segments are separated by long distances.
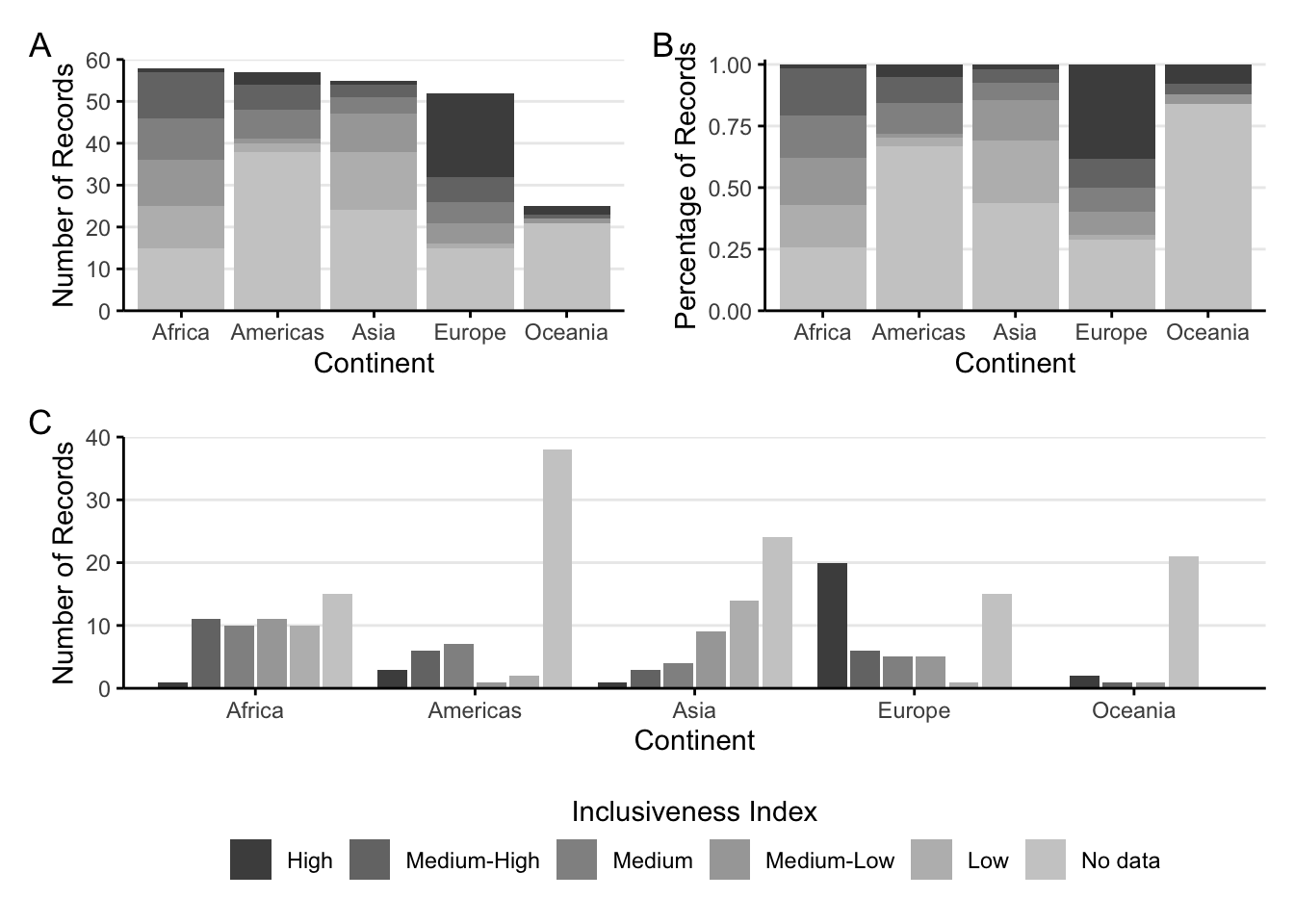
FIGURE 1.4: Three bar charts with color. A: A sample stacked bar chart. B: A sample filled stacked bar chart. C: A sample grouped bar chart.
1.2.2.1 Variation: Dumbbell plot
Stacked and grouped bar charts show some of the limitations of bar charts for making complex comparisons. The rectangles in the bar chart take up a large amount of space. Think back to the lollipop plot, where it’s the circles that directly represent the data value. Converting bars to something like circles opens up the ability to make more direct comparisons.
For example, let’s say we want to compare two continents more directly: Asia and Europe.
Figure 1.5 part A groups all of the segments by continent, which makes it easy to compare different Index categories within a single continent. What if we want to bring more attention to the difference between continents for each category? We could always switch which category is the primary division on the x axis and which is represented by color (figure 1.5 part B).
This improves our ability to compare the continents directly because the bars are directly next to each other. The amount of space the bars take up is still pretty large, though. If we combine this chart with something like a lollipop plot, we get one last variation: a dumbbell plot (figure 1.5 part C).
With a dumbbell plot, we use a circle to represent the data values, just like the lollipop. Instead of having a line that extends all the way to the axis, though, we use a line to connect the two dots in each category of Inclusiveness Index.
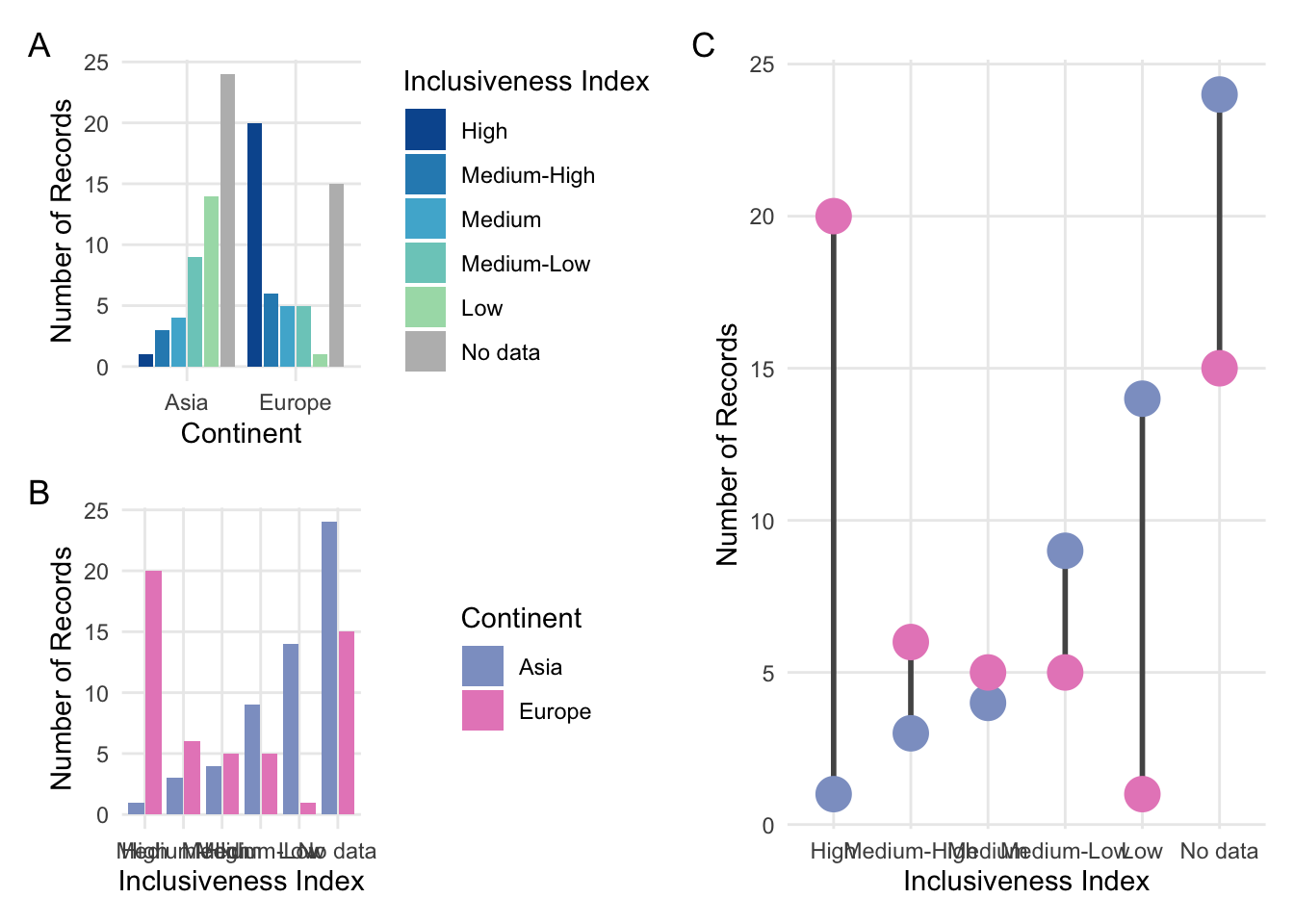
FIGURE 1.5: A: A grouped bar chart focusing on two continents. B: The same grouped bar chart with a different arrangement of the categorical variables. C: A dumbbell plot comparing two continents.
With a dumbbell plot, there are three main trends we can explore in the chart. We can focus on the green circles to see the pattern in the Asia data values. We can focus on the blue circles to see the pattern in the Europe data values. Finally, we can focus on the lengths of the lines connecting the circles to compare the continents at each level of the Inclusiveness Index. This chart type is an efficient way to compare these data values, but remember that it can be difficult to compare the lengths of shapes when they don’t have the same baseline.
1.3 Scatter Plot
The scatter plot is another common visualization type. This type of visualization displays one circle for each record in the data set. The position of the circle is based on the values of two different numerical variables, one of which is associated with the x axis and the other of which is associated with the y axis.
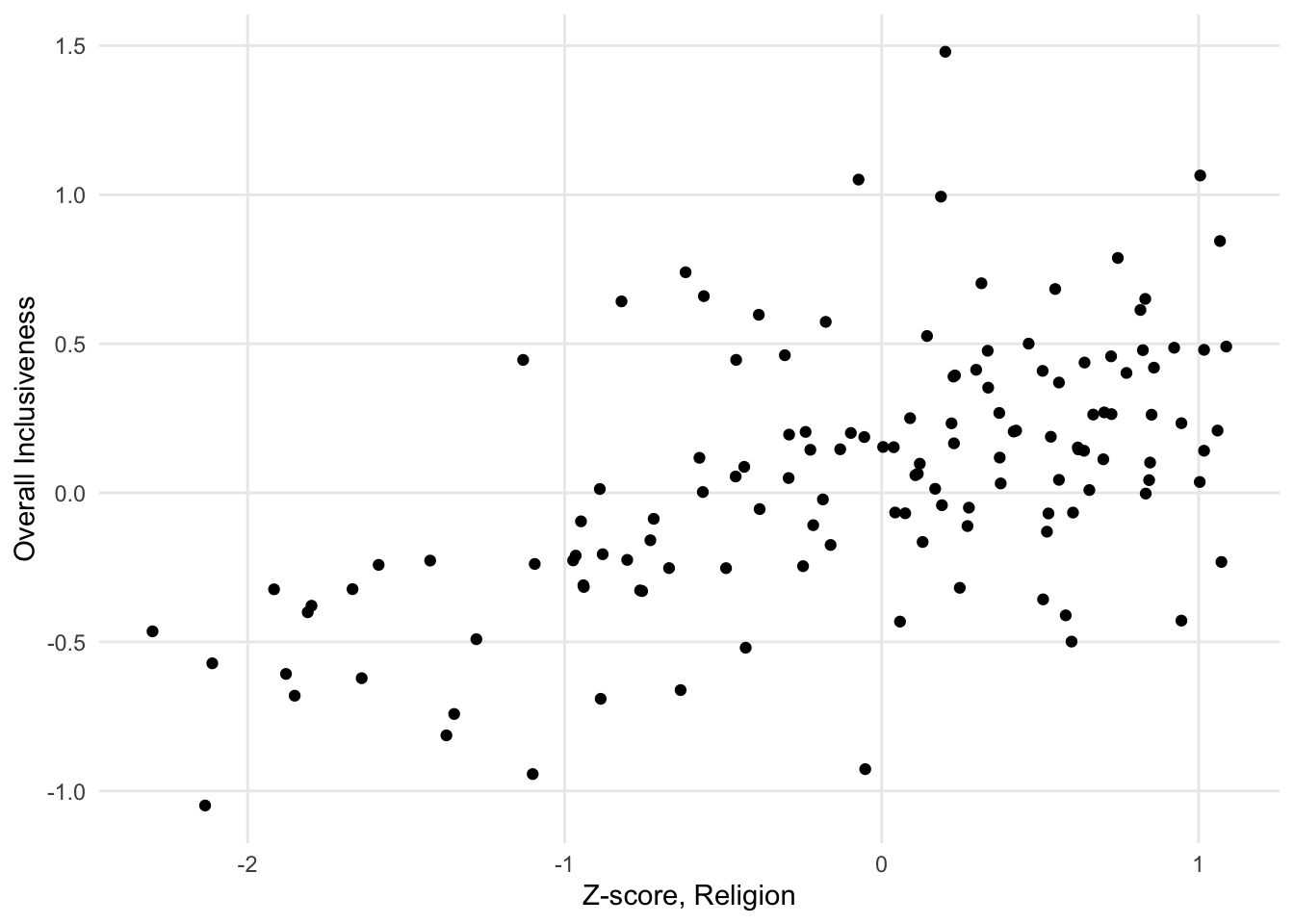
FIGURE 1.6: A sample scatter plot.
This visualization is a way to show a relationship between the two numerical variables displayed on the axes. A relationship between the variables means that a change in one variable would predict a specific kind of change in the other variable. For example, one kind of relationship is a positive correlation, which means that an increase in one variable is associated with an increase in the other variable. Points with higher values on the x axis tend to have higher values on the y axis. Similarly, points with lower values on one axis tend to have lower values on the other axis.
When two numerical variables have a positive correlation, it shows up on the scatter plot as a diagonal pattern of circles, from the bottom left corner of the chart to the upper right corner of the chart. The closer it looks to a straight line, rather than a diffuse pattern, the stronger the relationship is.
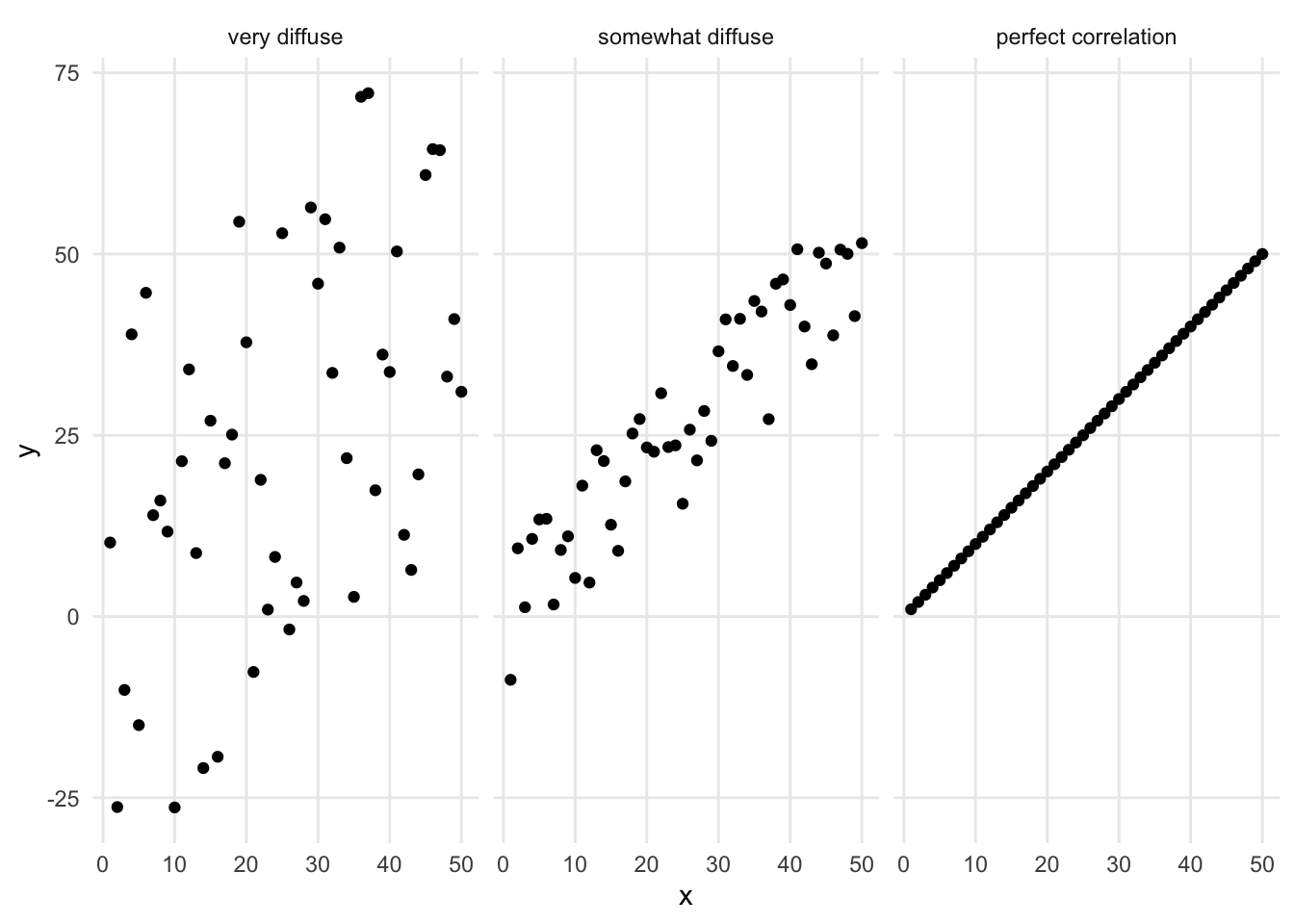
There are a few types of patterns that might show up when looking at a scatter plot. Instead of a positive correlation, the variables could have a negative correlation: high values of one variable are associated with low values of the other variable. This relationship shows up on the scatter plot as a diagonal patter from the top left corner to the bottom right corner.
Both positive and negative correlations are linear relationships - they look like lines on the chart. There are also nonlinear relationships that look like different kinds of curves. An exponential relationship looks like a curve that starts mostly horizontal and then curves up dramatically, ending up almost vertical. A logarithmic relationship is a curve that starts mostly vertical and bends over dramatically, ending up almost horizontal. Other curvilinear patterns of dots might be better represented by other mathematical functions.
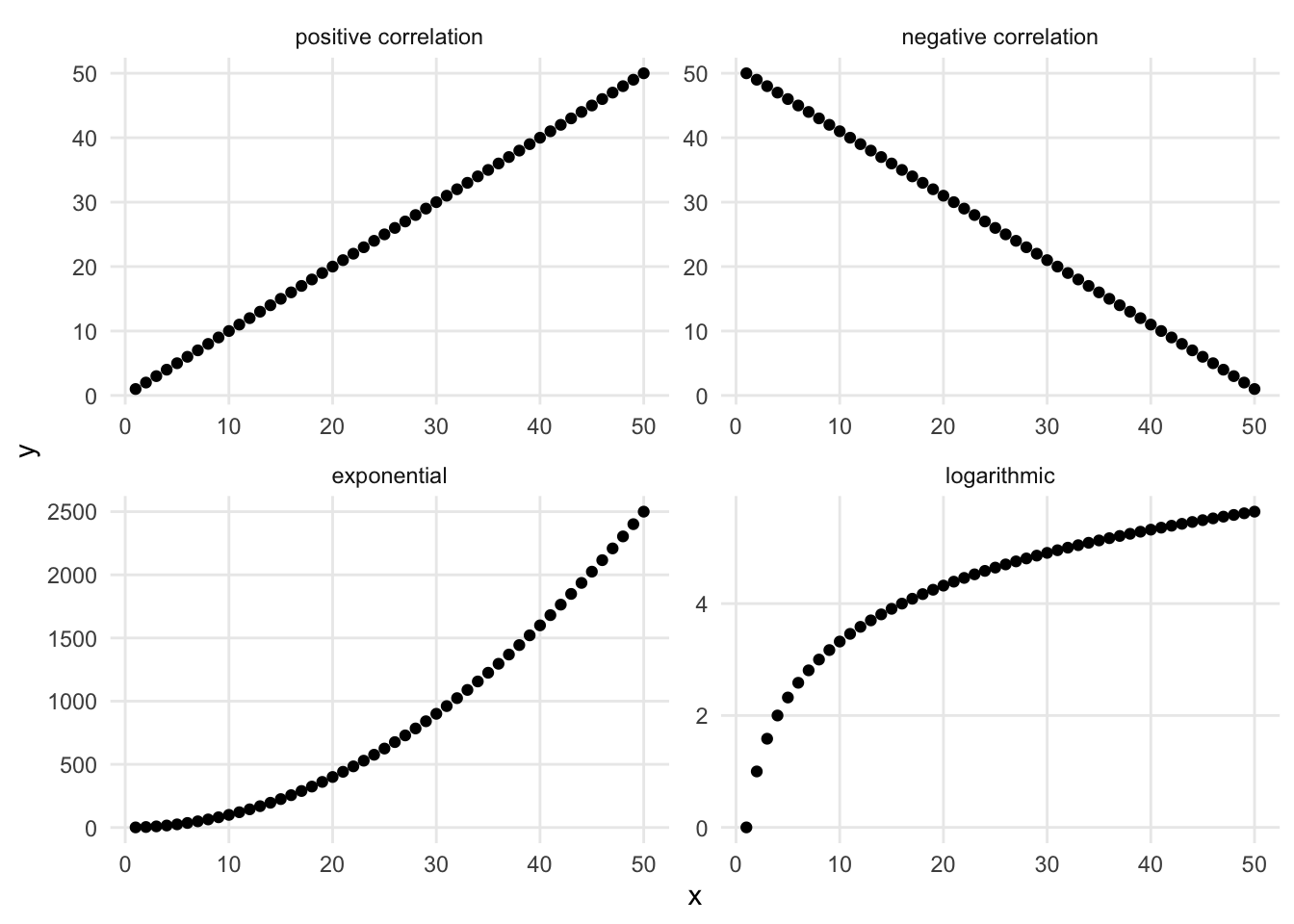
FIGURE 1.7: Different relationships between numerical variables.
What does it mean to see a shape in a scatter plot? A detectable shape in a scatter plot is a suggestion that there might be a statistically powerful relationship between these variables. The chart, however, is not a substitute for a statistical analysis. Using statistical analyses to explore the relationship between two variables is called modeling.
Sometimes a scatter plot will be combined with a statistical model to explore the connection between the data points and an ideal relationship. For example, you may see a scatter plot where there is a correlation between the variables combined with a linear model (represented by a straight line drawn on top of the points).
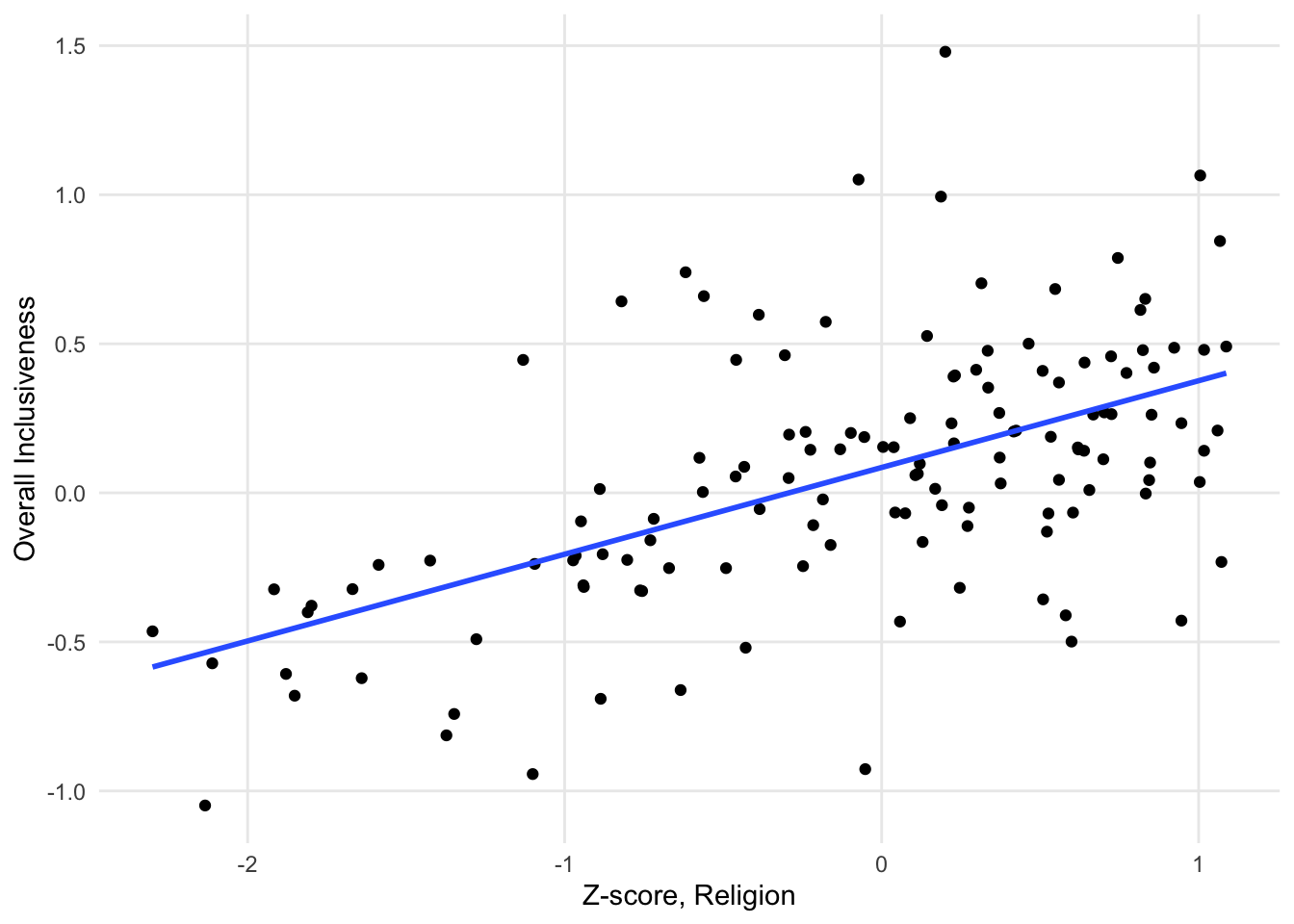
FIGURE 1.8: A sample scatter plot with a linear model overlaid over the points.
When you see a line on a scatter plot like this, it is showing the linear model that best represents the relationship between the x and y variables. In this case, the relationship between the variables is not very strong, so the points look more like a cloud than the straight line of the linear model.
1.3.1 Variations
The following charts are variations on a scatter plot. They build on a basic scatter plot by summarizing the data and making it easier to see patterns.
1.3.1.1 Contour or density plot
Sometimes a dataset is too large for a scatter plot to be effective. With a large number of data points, there can be too much overlap between the circles to see the dominant patterns. In this instance, it can be helpful to calculate the density of data points across the chart and visualize the density instead of (or in addition to) the points. This is called a contour or density plot.
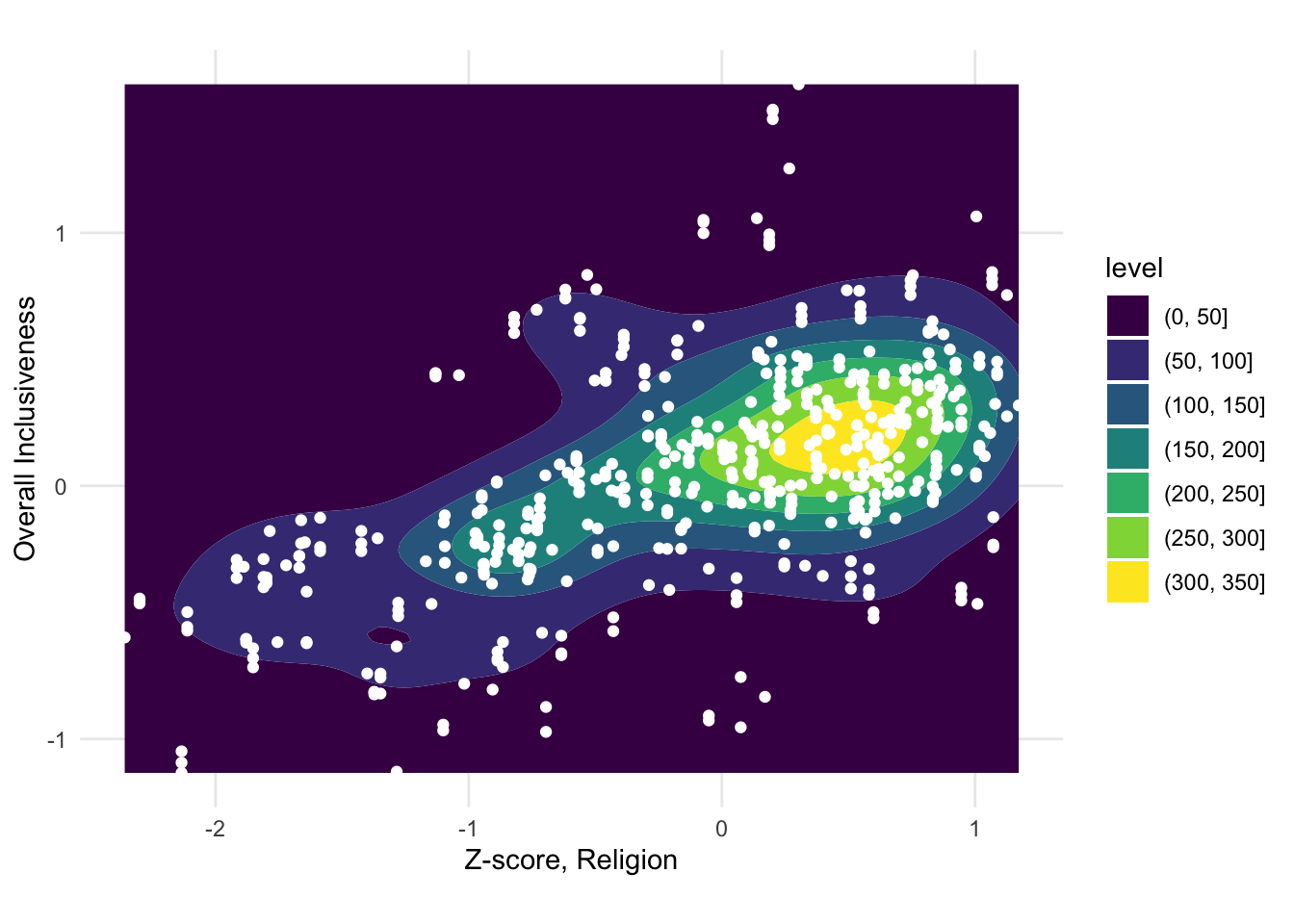
FIGURE 1.9: A sample contour plot with scatter plot points on top.
1.3.1.2 Binned scatter plot
In a contour plot, the density calculation detects regions of high density in a scatter plot. Another way of summarizing the distribution of points across the plot is to divide the plot into an even grid and then to count the points inside each region. This is often called “binning.” Common types of binning are rectangular (splitting the plot up using a rectangular grid) and hexagonal (splitting the plot up using a grid of interlocking hexagons).
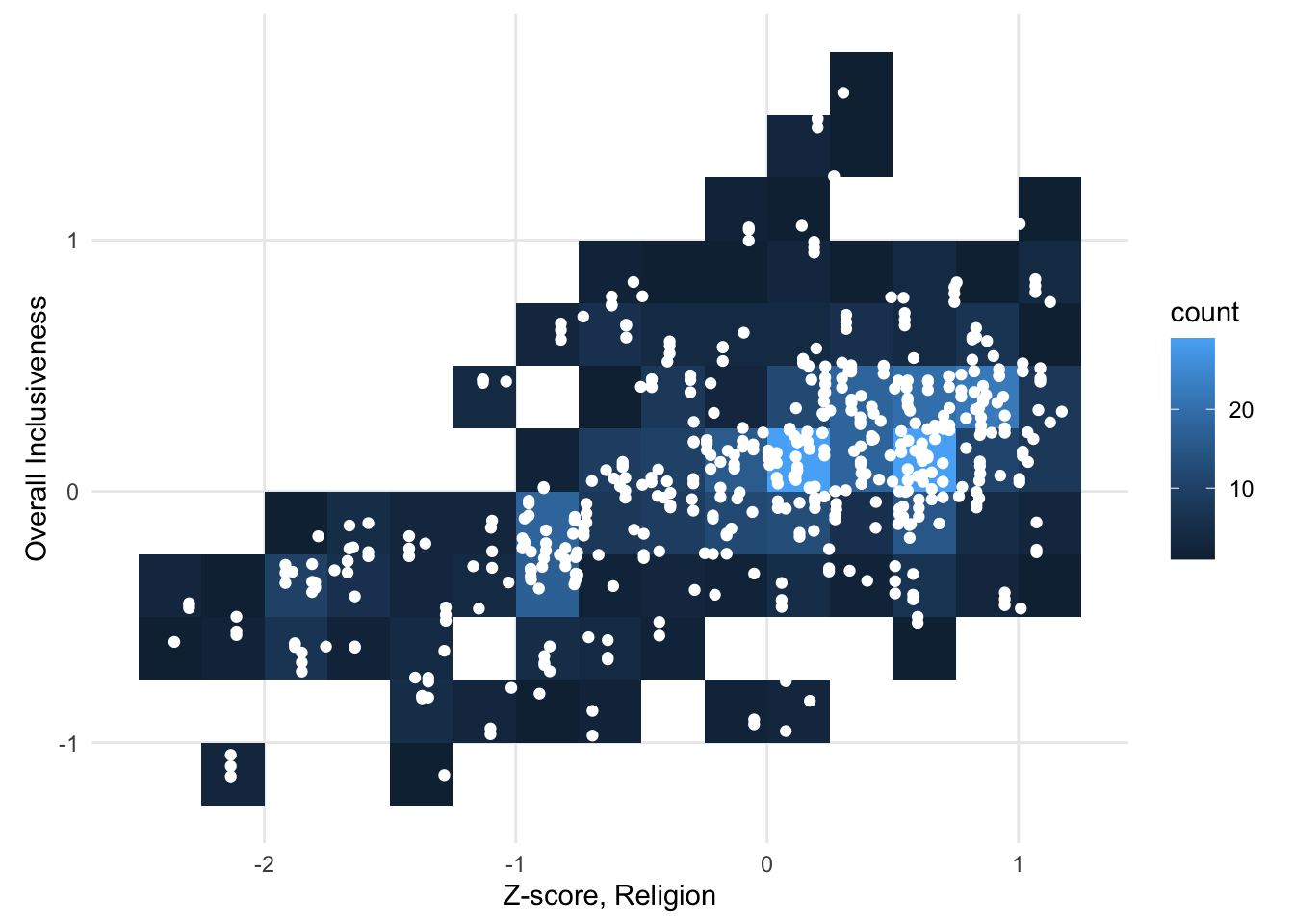
FIGURE 1.10: A sample scatter plot binned with a rectangular grid.
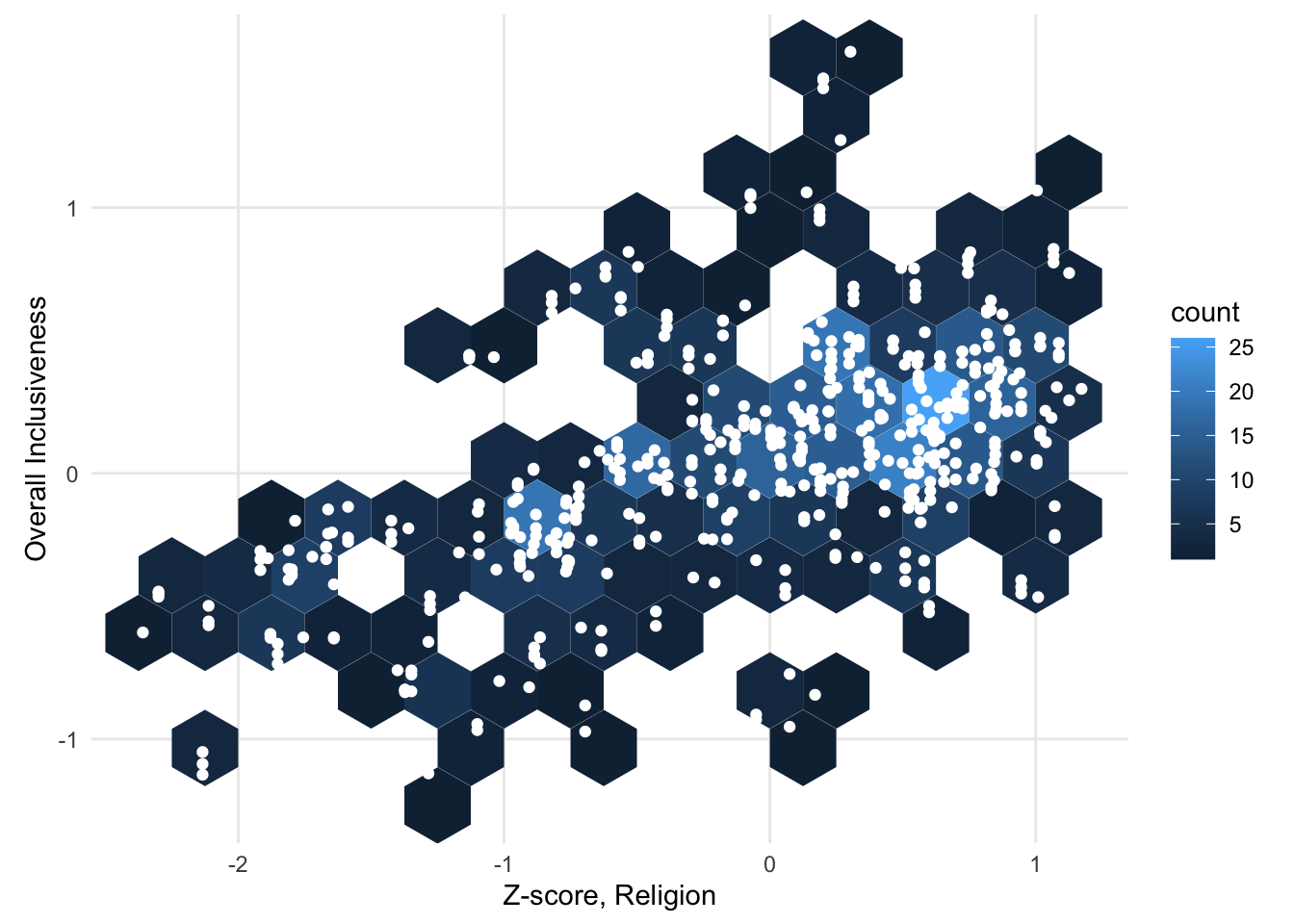
FIGURE 1.11: A sample scatter plot binned with a hexagonal grid.
1.3.2 Add a variable: Scatter plot with color
So far, our scatter plots have still only been used to visualize the relationship between two numerical variables. In some datasets, it can be helpful to consider how an additional variable interacts with the scatter plot pattern. One way to incorporate an additional variable is to change the color of the points in the scatter plot according to the third variable. For example, you can associate the color of the points with a categorical variable to show whether different subsets of the points cluster in different parts of the graph.
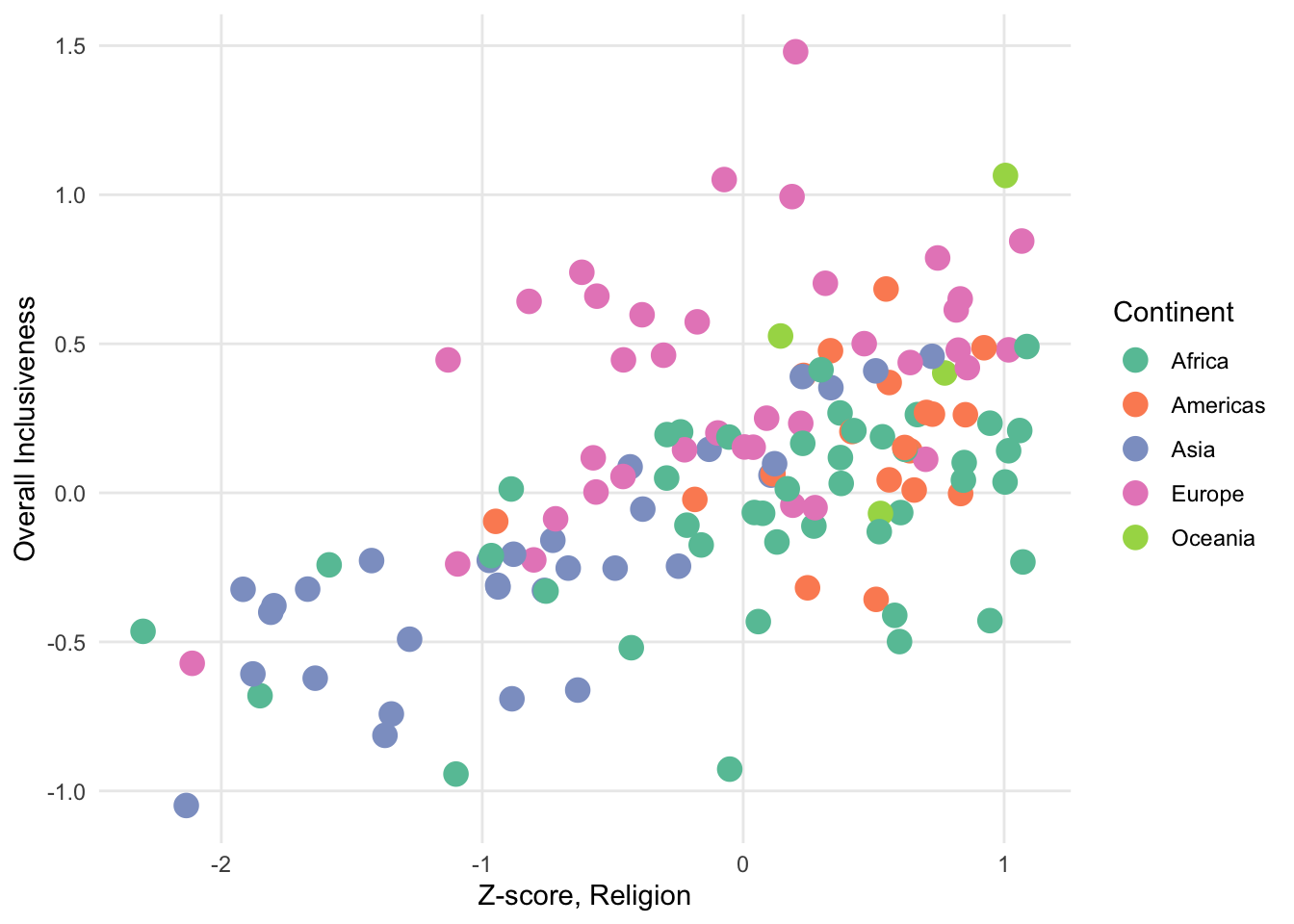
FIGURE 1.12: A sample scatter plot with color categories.
In the above chart, the color represents the continent; that is, each continent shows as a separate color. We’re looking for a relationship between the pattern of the colors and the spatial pattern of the points. In this chart, the points associated with Europe do overall seem to cluster in the upper-right corner of the graph, meaning that on the whole the European countries tend to rate highly on both the Z-score value for religious inclusiveness and the overall inclusiveness score. African countries also tend to have high scores for religious inclusiveness, but they don’t rate as highly for overall inclusiveness.
You can also use color to visualize a third numerical variable instead of a categorical variable.
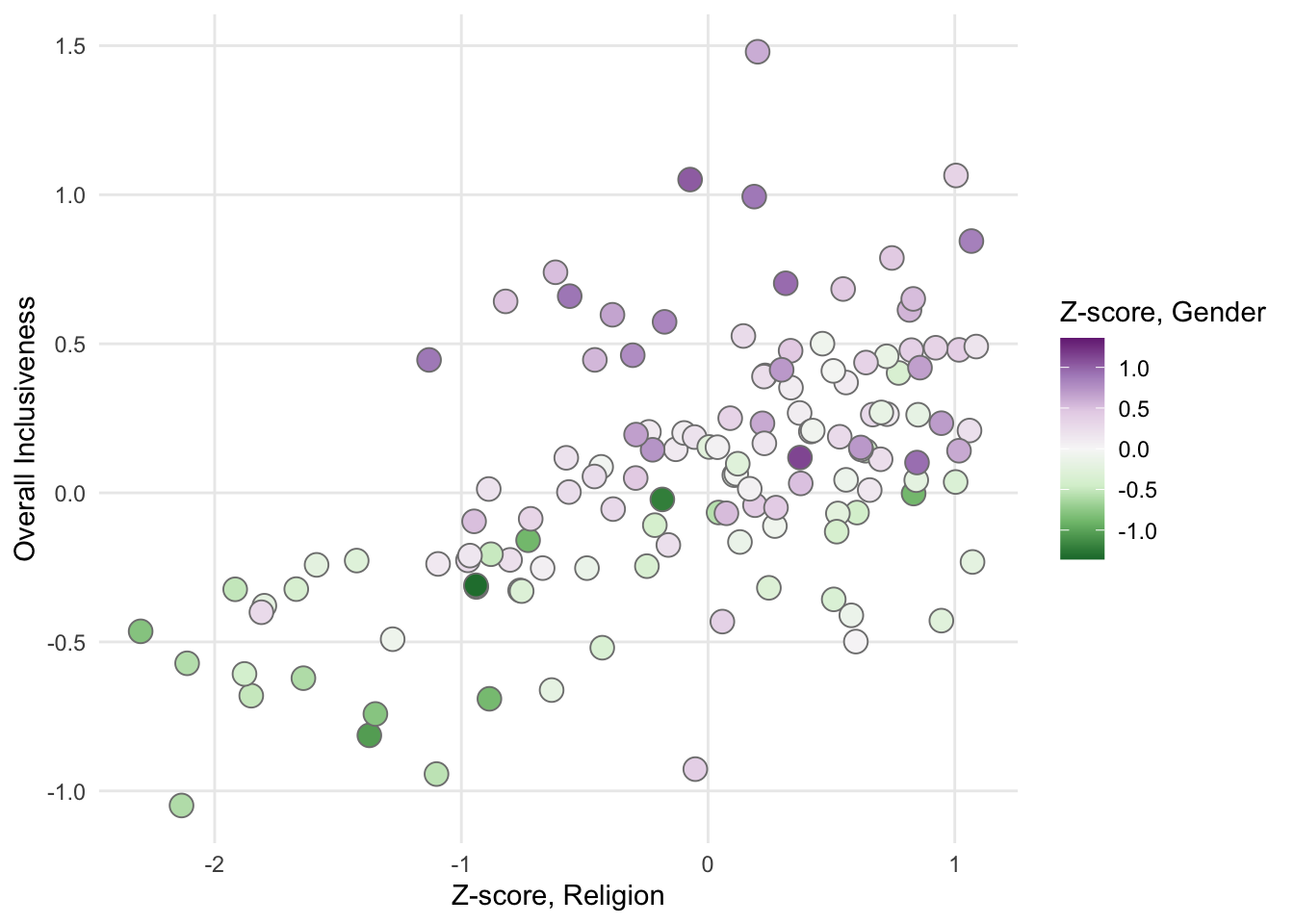
FIGURE 1.13: A sample scatter plot with a color gradient.
In this chart, the values in the “Z-score, Gender” variable are associated with a color gradient. Positive values of this new variable show in the chart as increasingly darker shades of purple. Negative values show as increasingly darker shades of green.
With any chart, adding more variables runs the risk of creating visual confusion that makes it harder (not easier) to see interesting patterns. For example, in the chart above, we see that purples mostly occur on the top half of the chart and greens on the lower half of the chart. Beyond that, though, it’s hard to identify a strong relationship between the strength of the color values and either of the axes. If colors are not concentrating in a particular region of the plot, adding a third variable may not be necessary for this chart.
1.3.3 Add a variable: Bubble chart
A bubble chart is another way of adding a third variable to a scatter plot. Unlike adding color to the chart, however, a bubble plot works best when you are adding a third numerical variable. That’s because in a bubble plot, the additional variable is represented by changing the size of the bubble. Representing a categorical variable by changing the size of the circle isn’t as natural as using different colors. It’s hard to focus on all of the bubbles of a particular size to try to identify clusters.
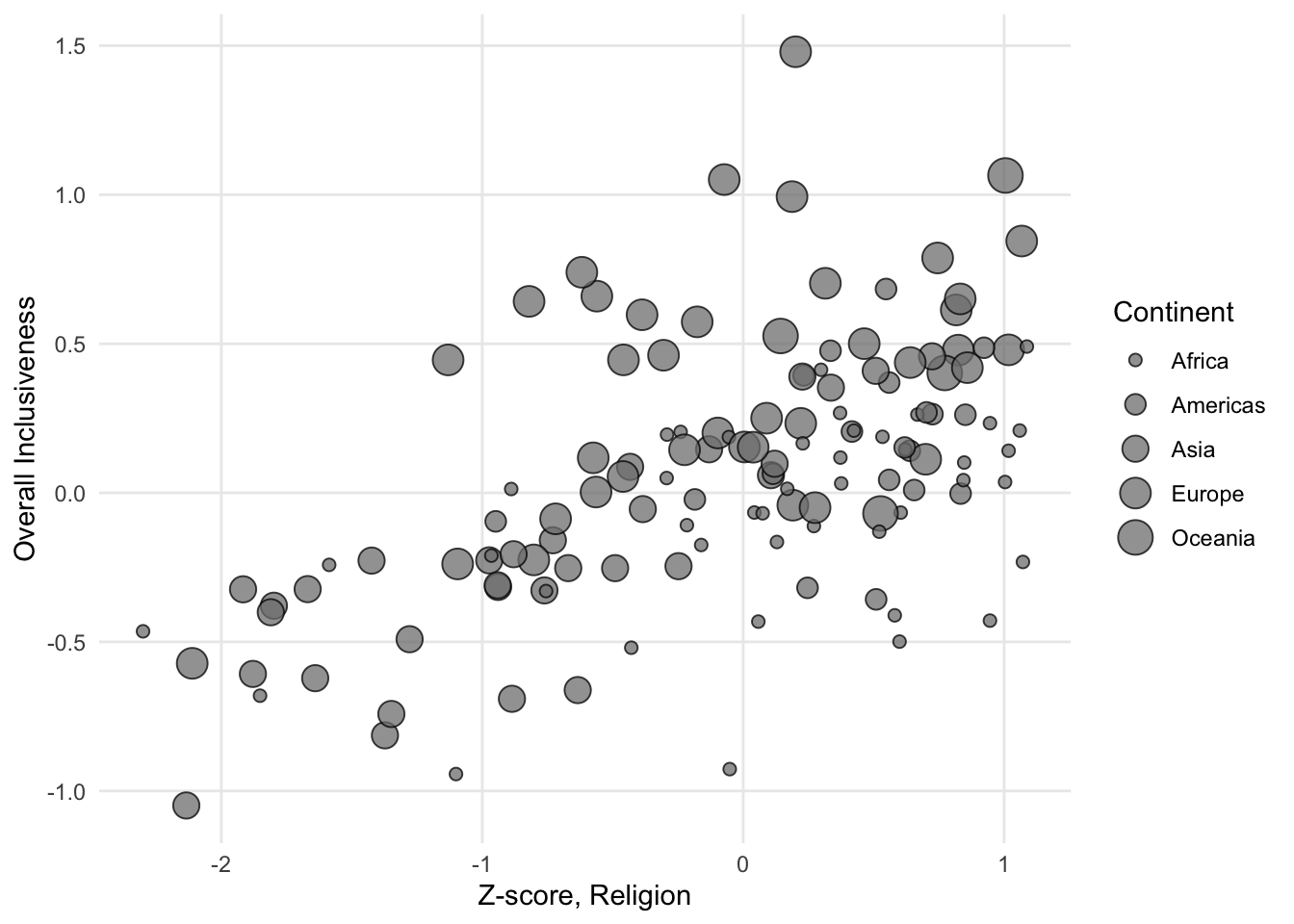
FIGURE 1.14: A sample bubble chart with categories.
If you use a numerical variable to size the bubbles, the goal of the chart becomes similar to when color is used to add a third numerical variable: explore whether the sizes of the bubbles changes in a meaningful way in relation to the axes.
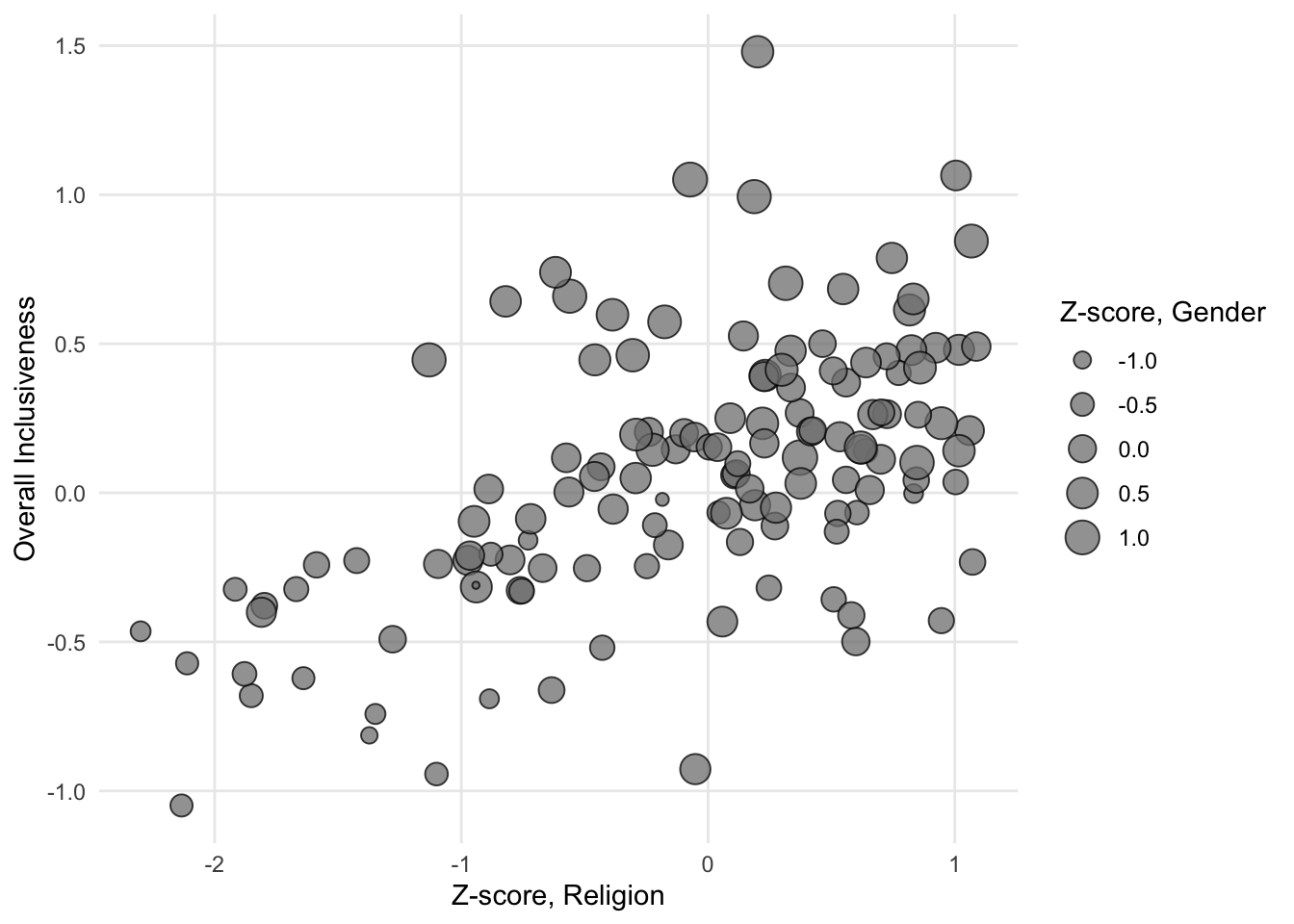
FIGURE 1.15: A sample bubble chart with a size gradient.
There is one property of bubble charts that is different from scatter plots with added color. When you have a variable that has both positive and negative values, it may be a slightly less natural fit for the size of the bubbles. The size of an object like a circle is naturally a positive value. A circle doesn’t itself have negative size. If the variable uses negative and positive in an abstract sense, though, the size of a bubble can still help differentiate low and high values.
With bubble charts, color is still available to display another variable if there is anything else that might interact with the three numerical variables.
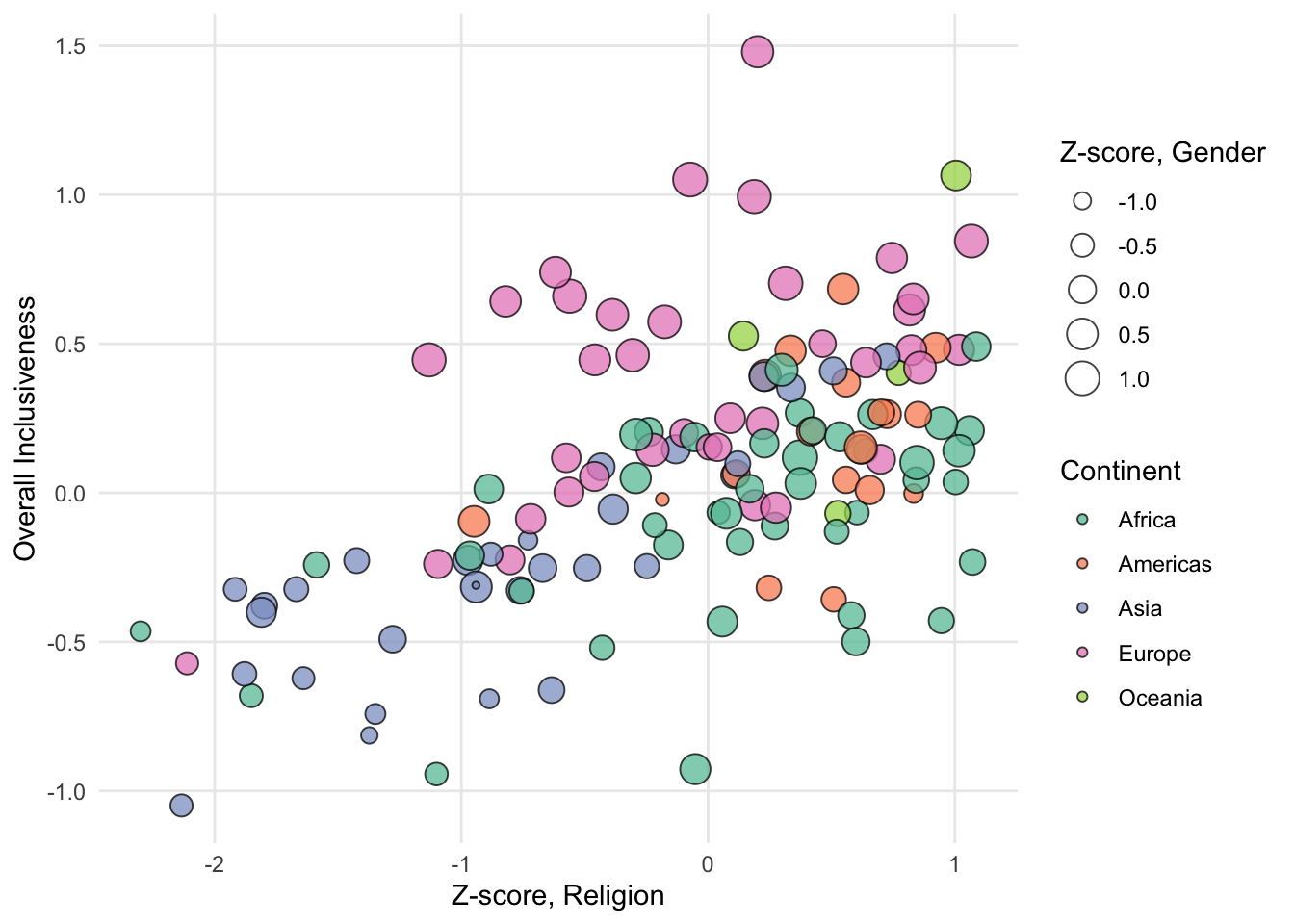
FIGURE 1.16: A sample bubble chart with color categories.
Be cautious, again, with adding too many variables to a single chart. If adding a variable doesn’t reveal anything new about the data, it is probably getting in the way of a pattern that does exist.
1.4 Line Chart
A line chart is typically used to explore the change in a numerical variable over time. The variable is measured over a series of time points (for example, years, days, seconds). The time variable is associated with the x axis of the chart, and the numerical variable is associated with the y axis. Instead of placing a circle for each record in the data set, like you would see in a scatter plot, the chart uses a line that travels through all of the correct data points. Connecting related points with a line gives the data a sense of continuity and motion. Line charts are often used to look for dramatic increases or decreases in the numerical value at particular points in time.
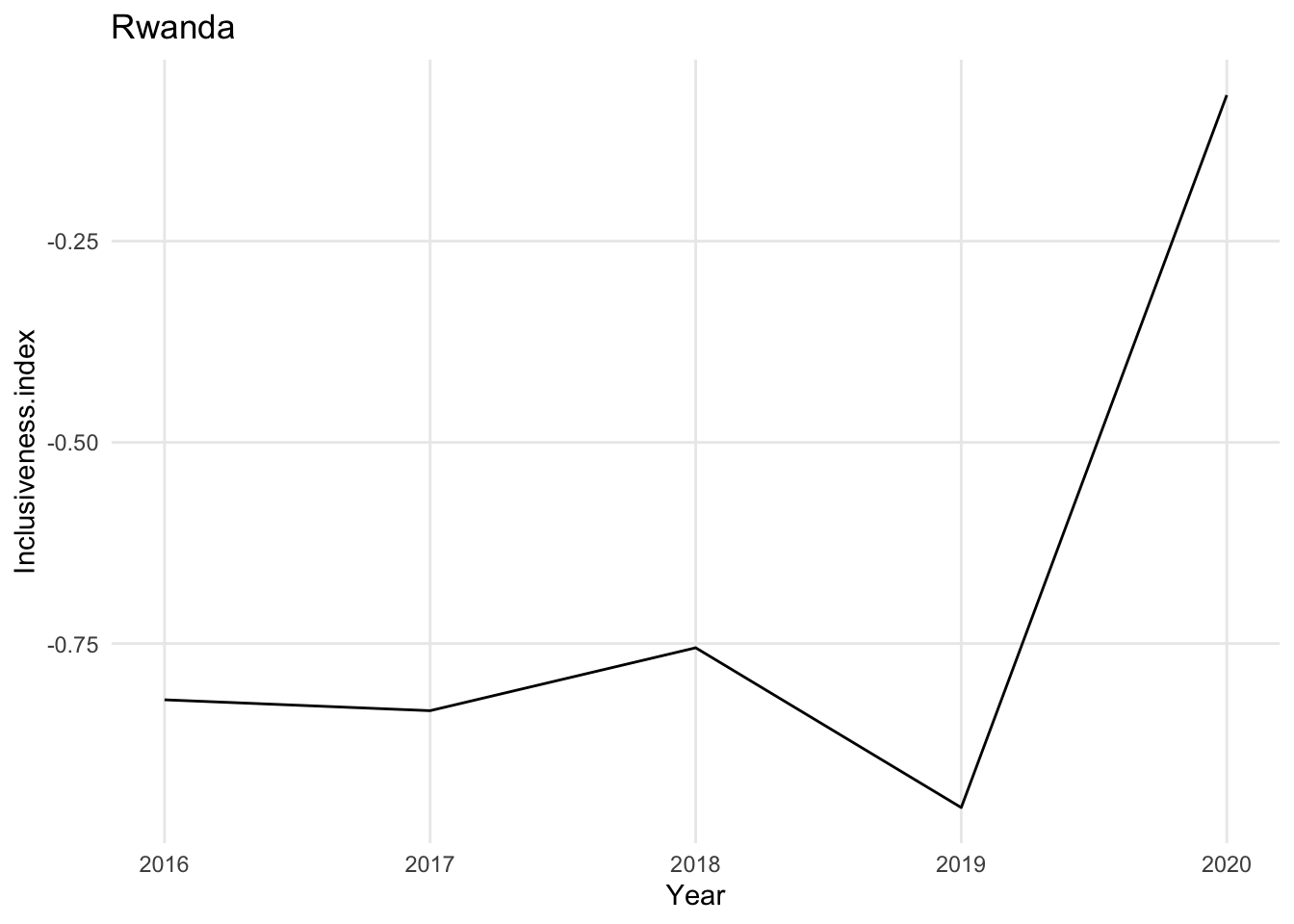
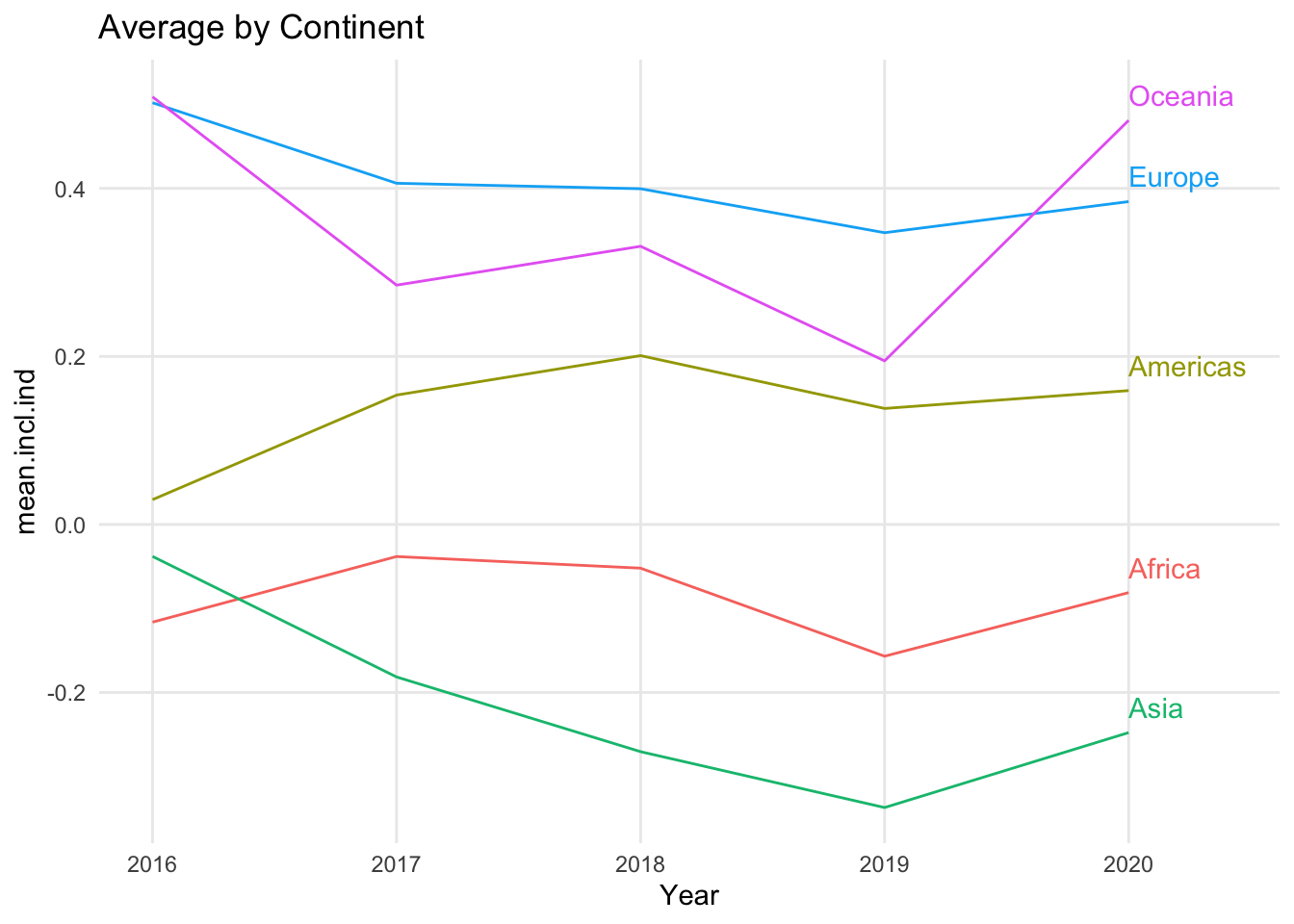
Line charts can show change over time for one entity or for many entities. In the example above, there is a single line representing a country. You can also use a line chart to show multiple lines at once. For example, if each line is a country, you can display many countries on the same chart to allow for comparisons between countries as well as over time.
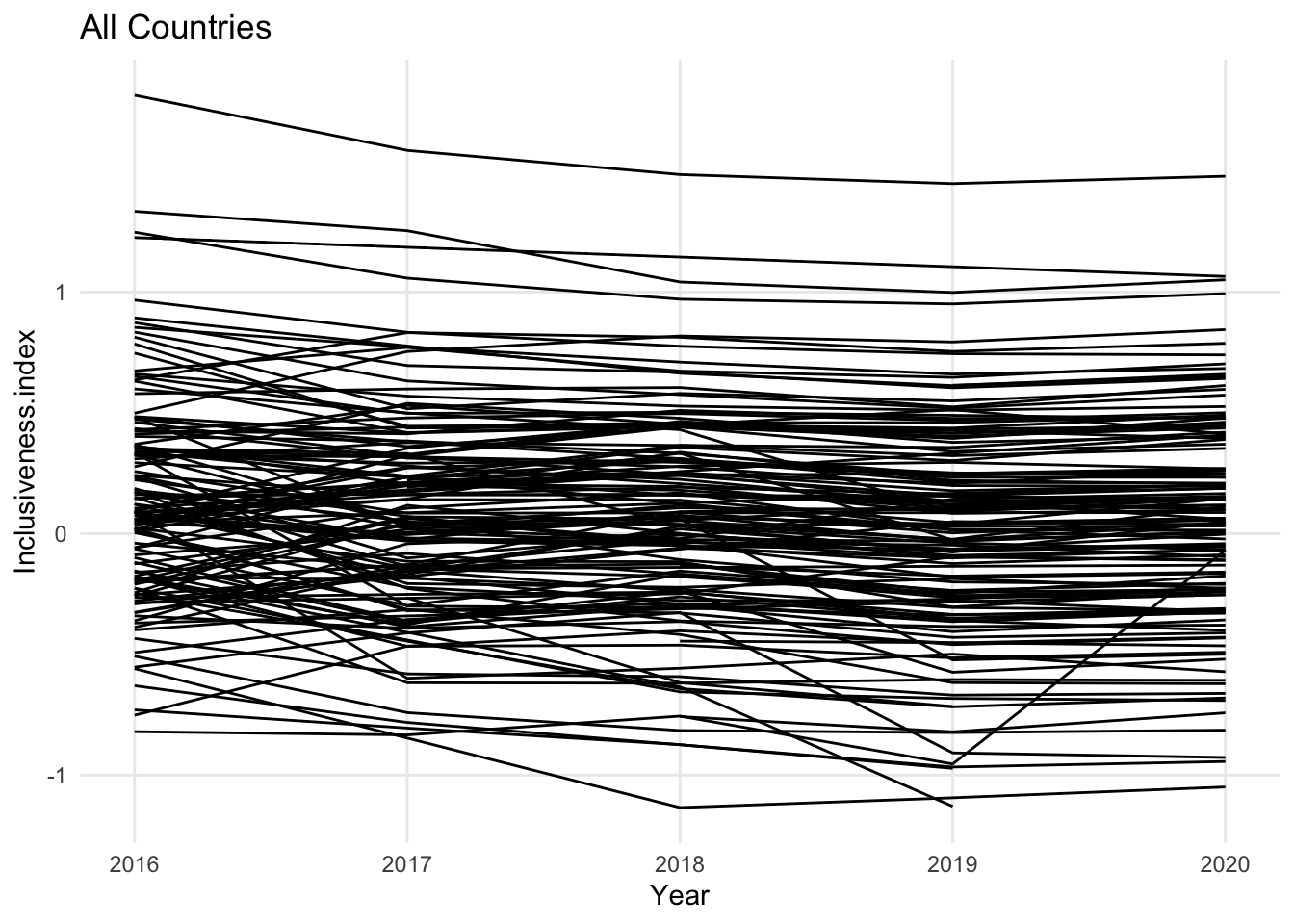
As with the other visualizations we’ve looked at, it is easy to create a line chart with so much data that it is hard to see patterns. The goal of the line chart is to show trends over time, but if all of the lines look flat, or if there are so many lines that you cannot detect the variations that are there, it may be useful to include only a small number of the lines at once, or to combine groups of the lines together.
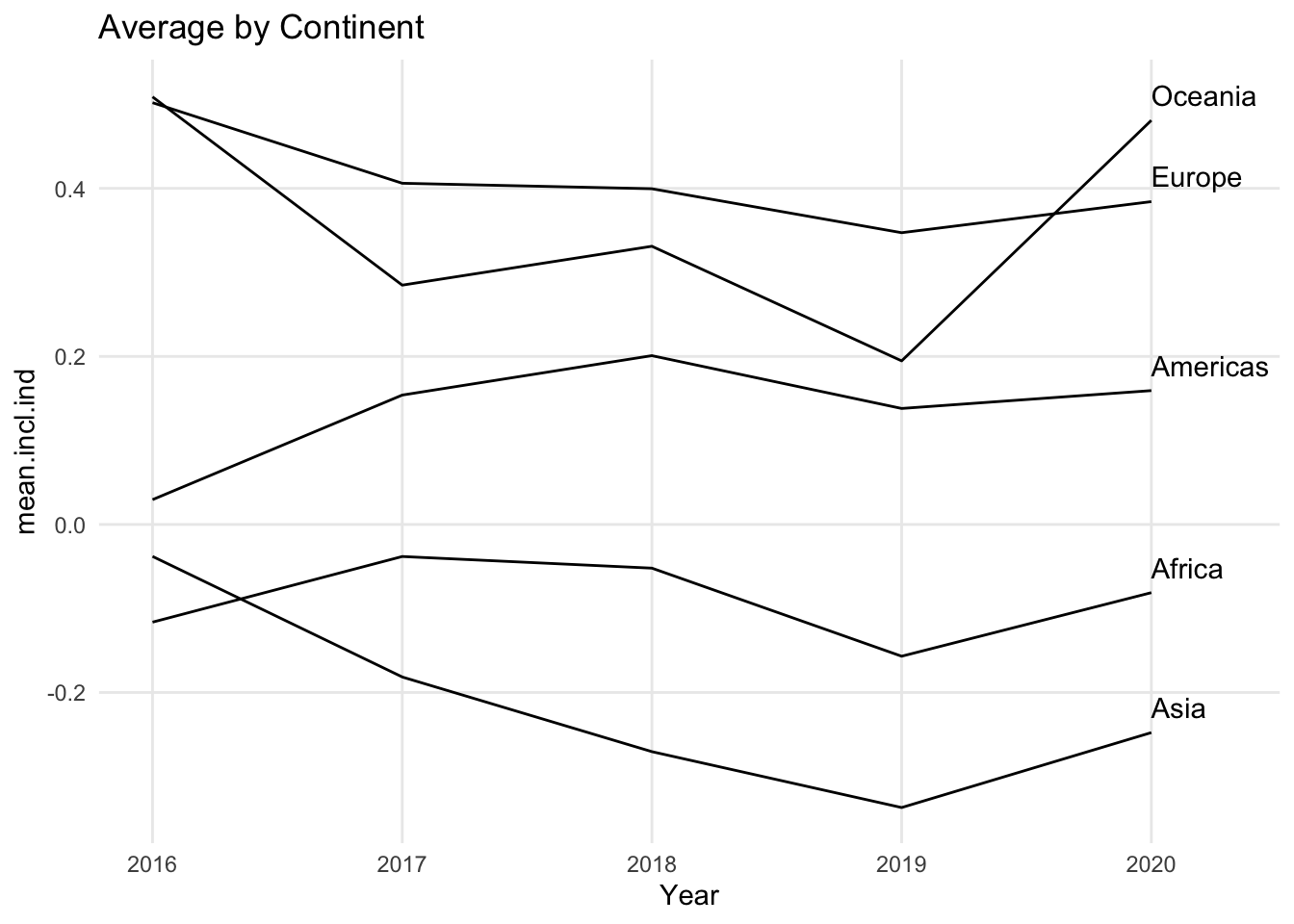
In this version of the chart, the countries from each continent have been combined into a single line using the mean of the countries’ values for each year. Another way to reduce the number of lines in the line chart would have been to limit the chart to the countries from a single continent.
Also notice that when you limit the number of lines you use in a line chart, it becomes much easier to identify each line with a label. Not every visualization includes labels for every data point. For example, in a scatter plot, you may not label the points if the important information is the overall trend. You may have the same situation in a line chart if all of the lines are moving in a similar direction, or they all experience a dramatic change at the same point. If it is important to identify specific lines in your chart, however, it is best to use only a few lines so that it is possible to identify each line directly and trace it individually across the entire chart.
1.4.1 Using circles to highlight the position of the data points
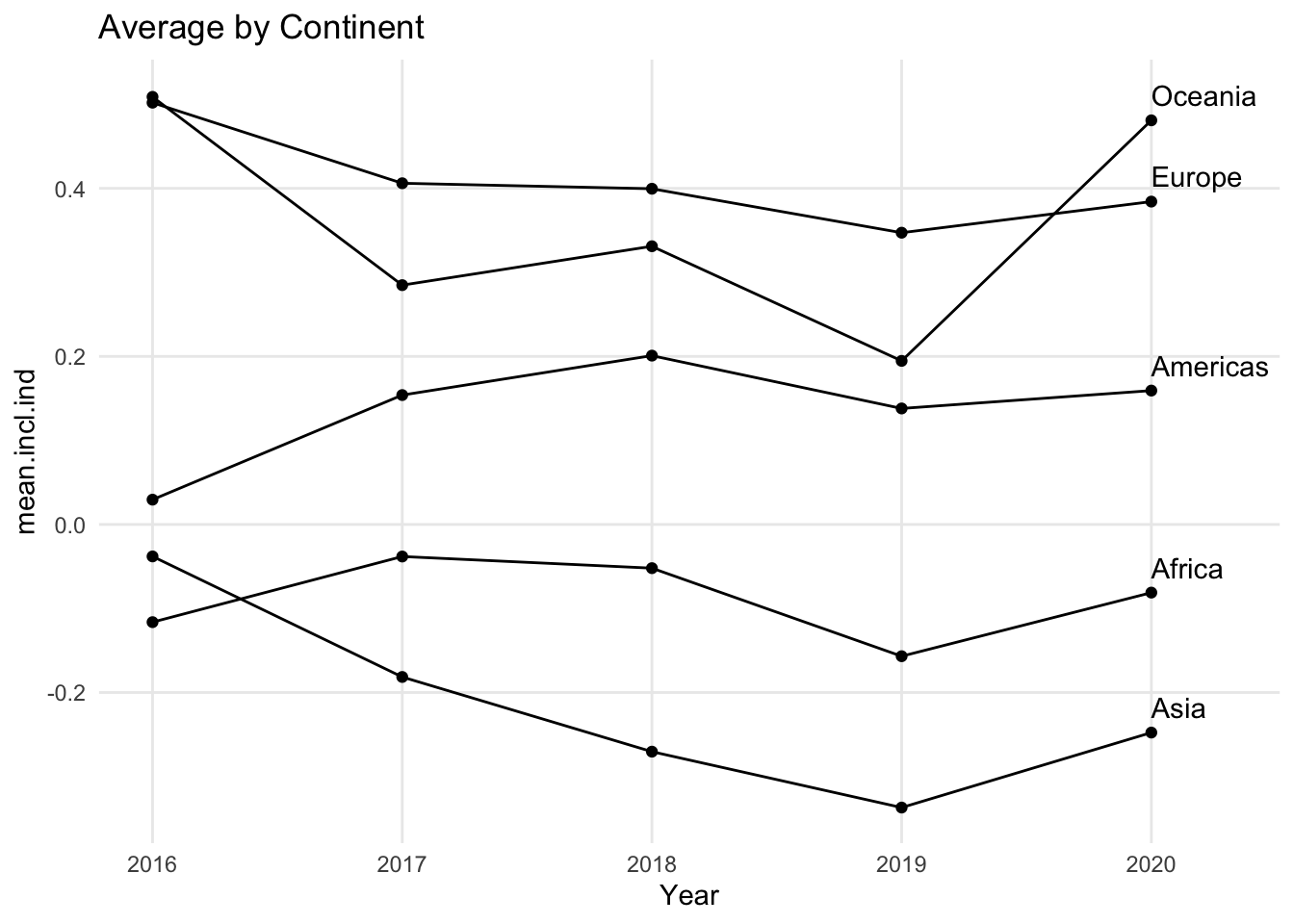
Some line charts include circles along the lines. These circles indicate that the data set included a value at that point in the line. This can be especially useful if lines travel through data at irregular time intervals. For example, if the data is collected every year except that there was a gap of three years in the middle, the circles would clearly indicate which years are included in the dataset and which are not. Normally the lines on a line chart will connect straight from one point in time to the next point in time, and unless the line turns up or down, it can be hard to know exactly where the real data values are.
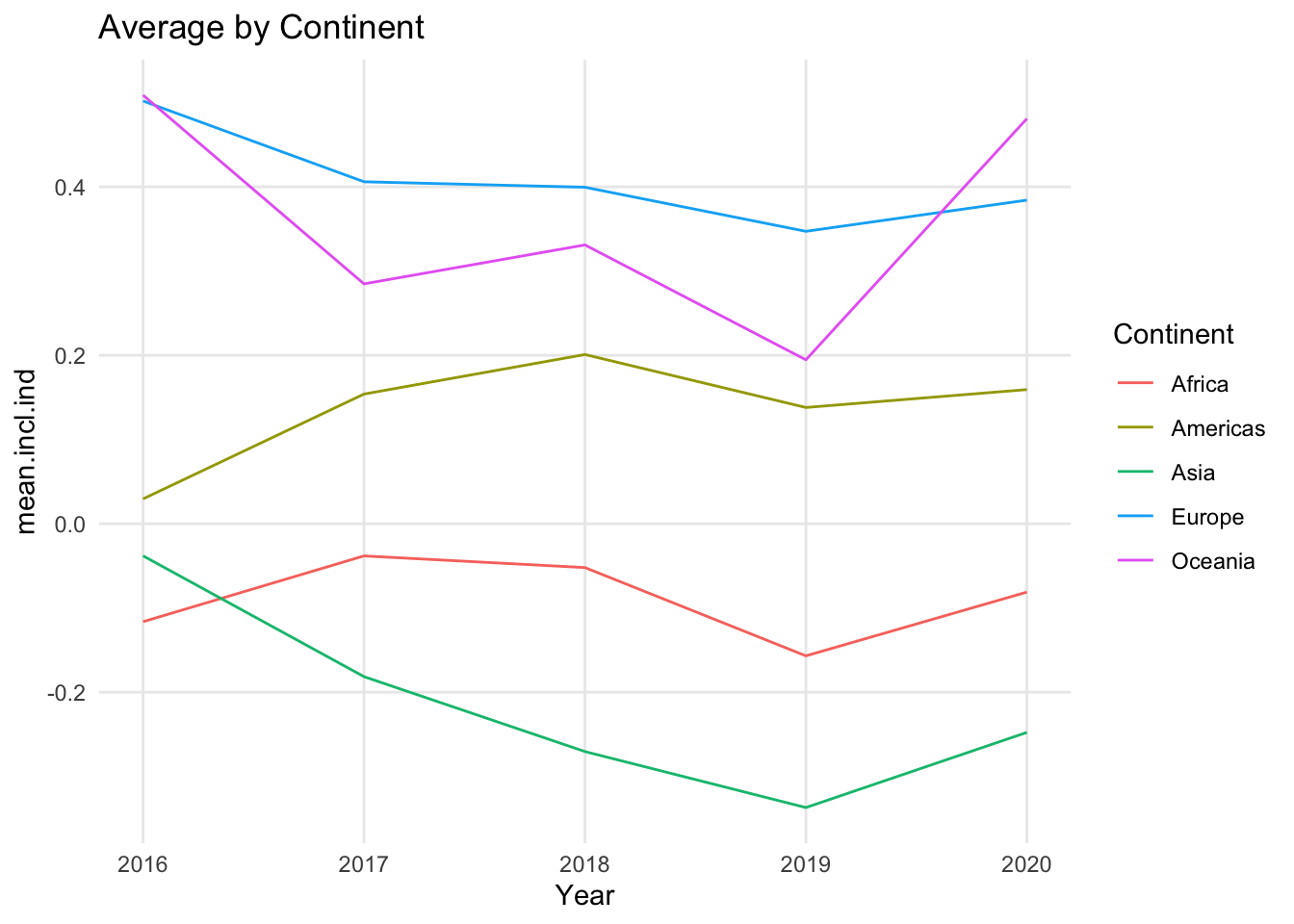
1.4.2 Using colors to distinguish individual lines
Sometimes line charts use color to differentiate the lines from each other. Each line gets its own color, and the color legend clarifies the name of the line. Even for charts where it is important to individually identify the lines, it can quickly become overwhelming to see a separate color for each line. Even a small number of lines can require a set of colors that include colors that are difficult to tell apart from each other. In additional, it can be confusing and time consuming to have to consult a legend to identify an individual line. While color may be a nice complement to a simple line chart, it is easier to read a line chart when the lines are labeled directly instead of relying on a legend.
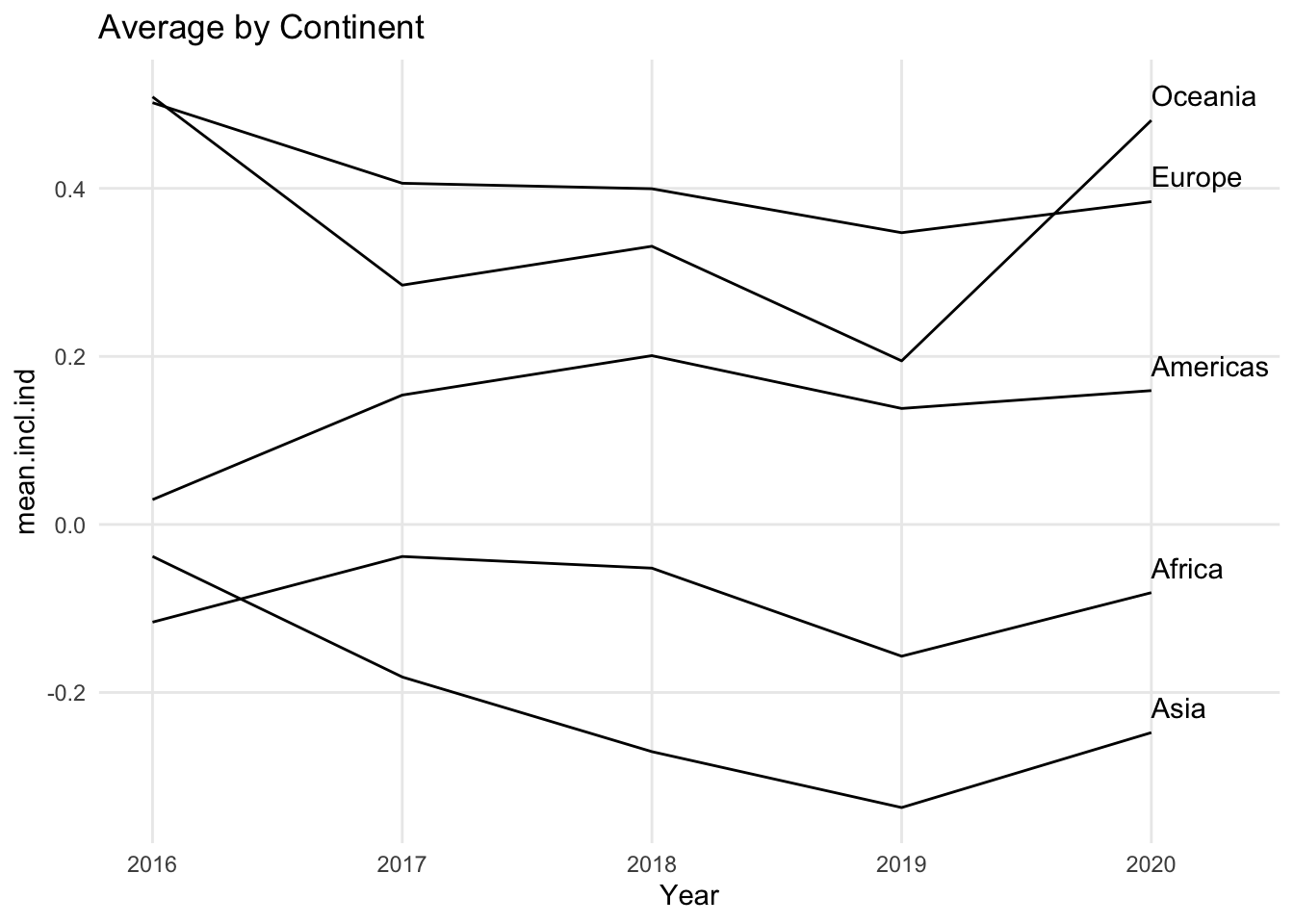
1.4.3 Variations
There is one primary variation of the line chart: the area chart.
1.4.3.1 Area chart
An area chart looks like a line chart where everything under the line, down to the x axis, has been colored in. If you took a typical line chart and color everything in under each line, though, you would have overlapping colors for much of the chart. It is more common to see a stacked area chart, which follows the same principles as a stacked bar chart. One line is chosen as the bottom line, and the values for each additional line are stacked on top of that line. The top most line shows the overall total of the data in the chart. For this reason, area charts should be used to show data points that can be added together, like counts.
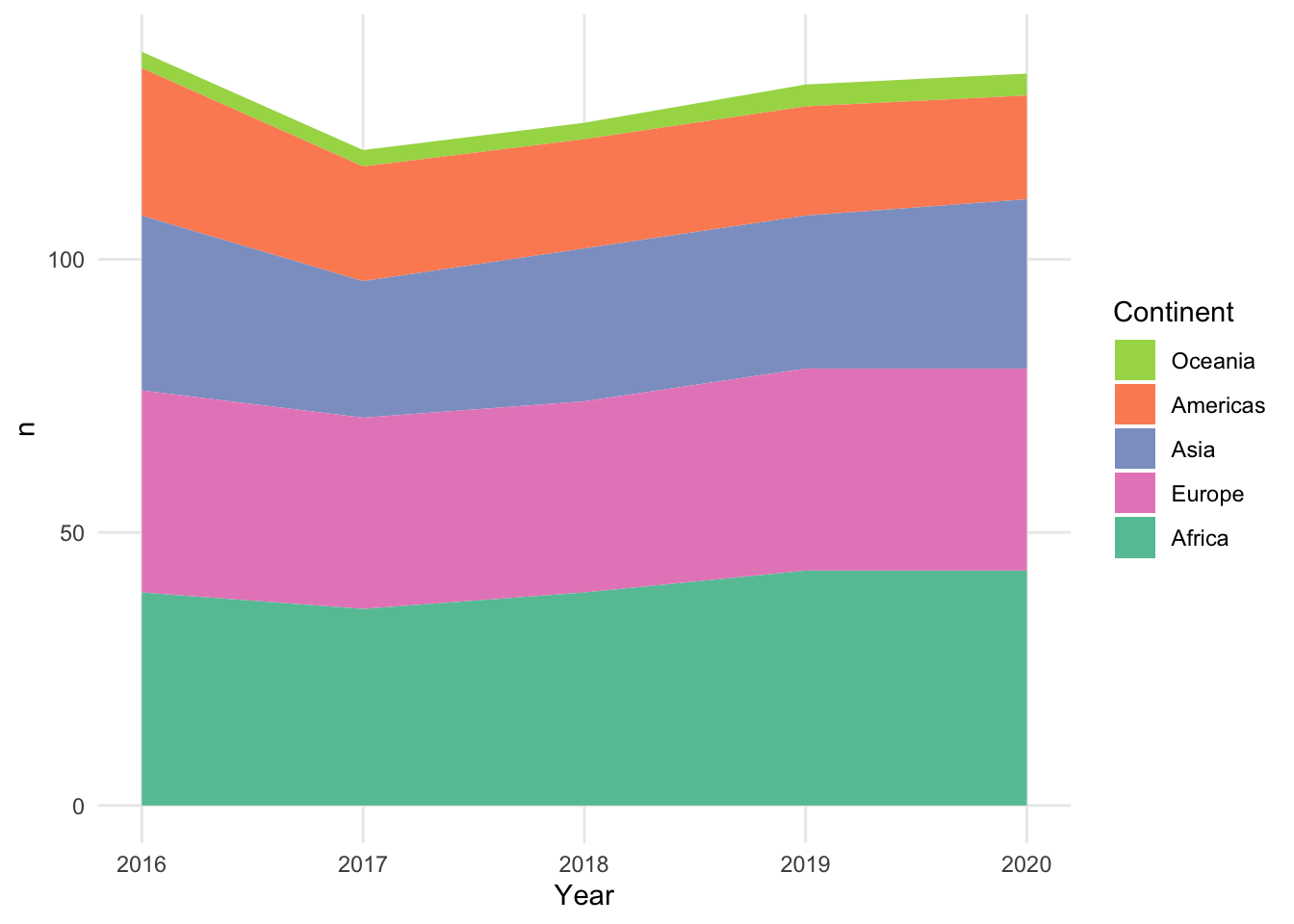
Stacked area charts raise concerns that are similar to the ones raised by stacked bar charts. The values for the lowest line and the overall total are easy to read, but the inner areas do not have a consistent baseline. It can be very difficult to see if an area has its own decrease at a particular year or if it is just reacting to a decrease in one of the lines below it.
1.4.4 Add a variable: Line chart with color
A common way to add a third variable to a line chart is to use color to represent a categorical variable, grouping the lines into different categories. This third variable could be unrelated to the variables already in the line chart, or it could be generated from the patterns in the chart – for example, creating a categorical variable that indicates whether the values are increasing or decreasing over time.
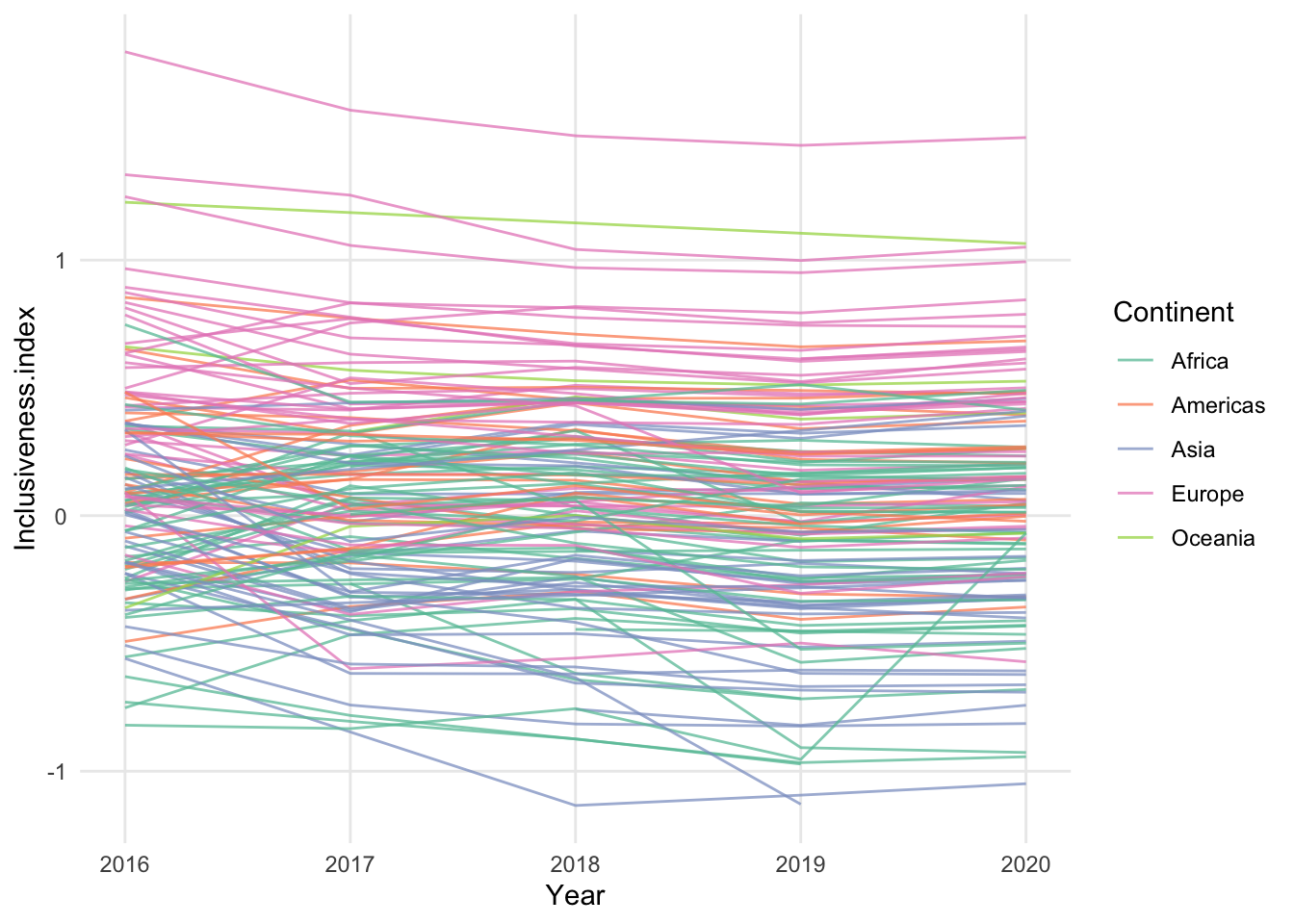
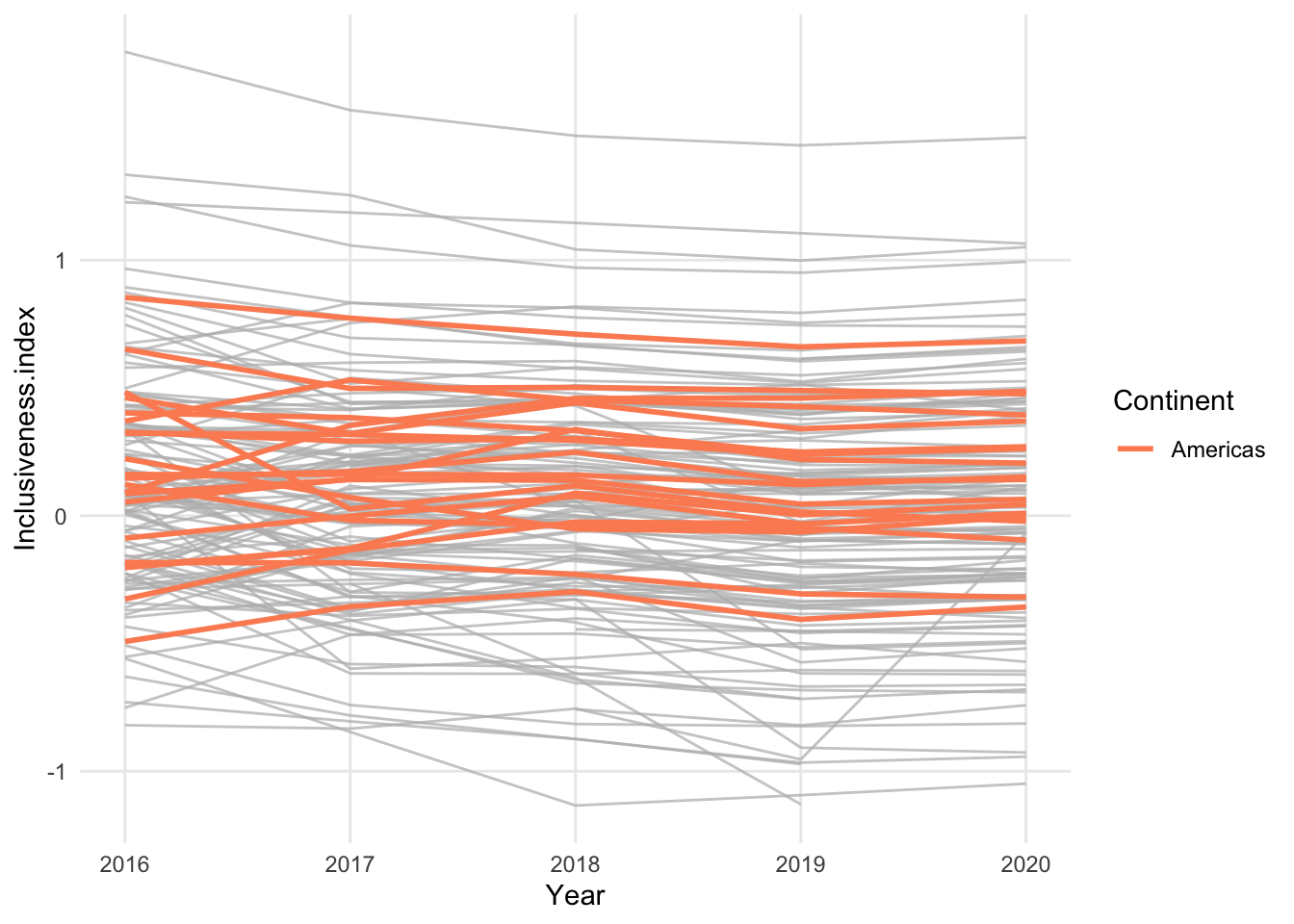
In the above chart, the individual country lines are colored by their continent. While this does reveal some general patterns for the continents, it also adds complexity to an already busy chart. Instead of using a different color for all possible continents, it may be easier to read a chart that focuses on a single continent and uses color to highlight just those countries.
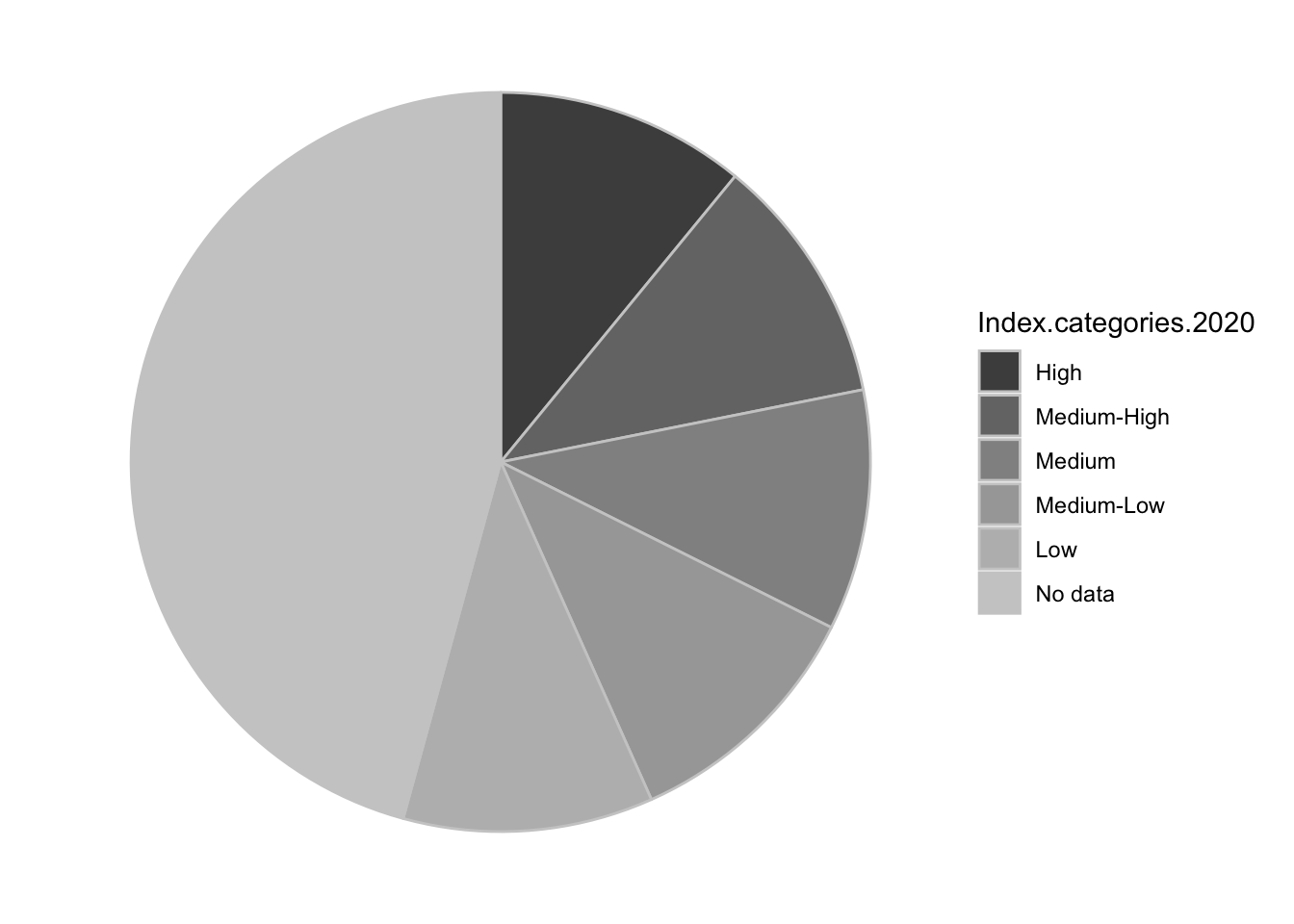
1.5 Pie Chart
- same data as a bar chart - categorical variable and numerical variable
- unlike a bar chart, the form of the pie chart means that only certain kinds of data make sense - categories that combine together to form a whole, numbers that are positive and make sense as a percentage of a whole
- hard to compare the size of wedges that are about the same size, especially when they’re rotated in space
- typically the wedges “start” at the top, and then usually the order goes around clockwise or counter-clockwise
- order matters (like bar chart)
- typical way of telling pie wedges apart is by color, but you can leave them all the same color and label them directly, like a line chart
- what are you looking for in a pie chart? You are looking for how the data are distributed between the wedges - are they mostly equal? Is one much larger than you would expect? Much smaller? How much of the total goes to each category?
- these comparisons become more complicated when you have a lot of wedges. If it’s important to understand small changes between the wedges, that can be difficult in a pie chart.
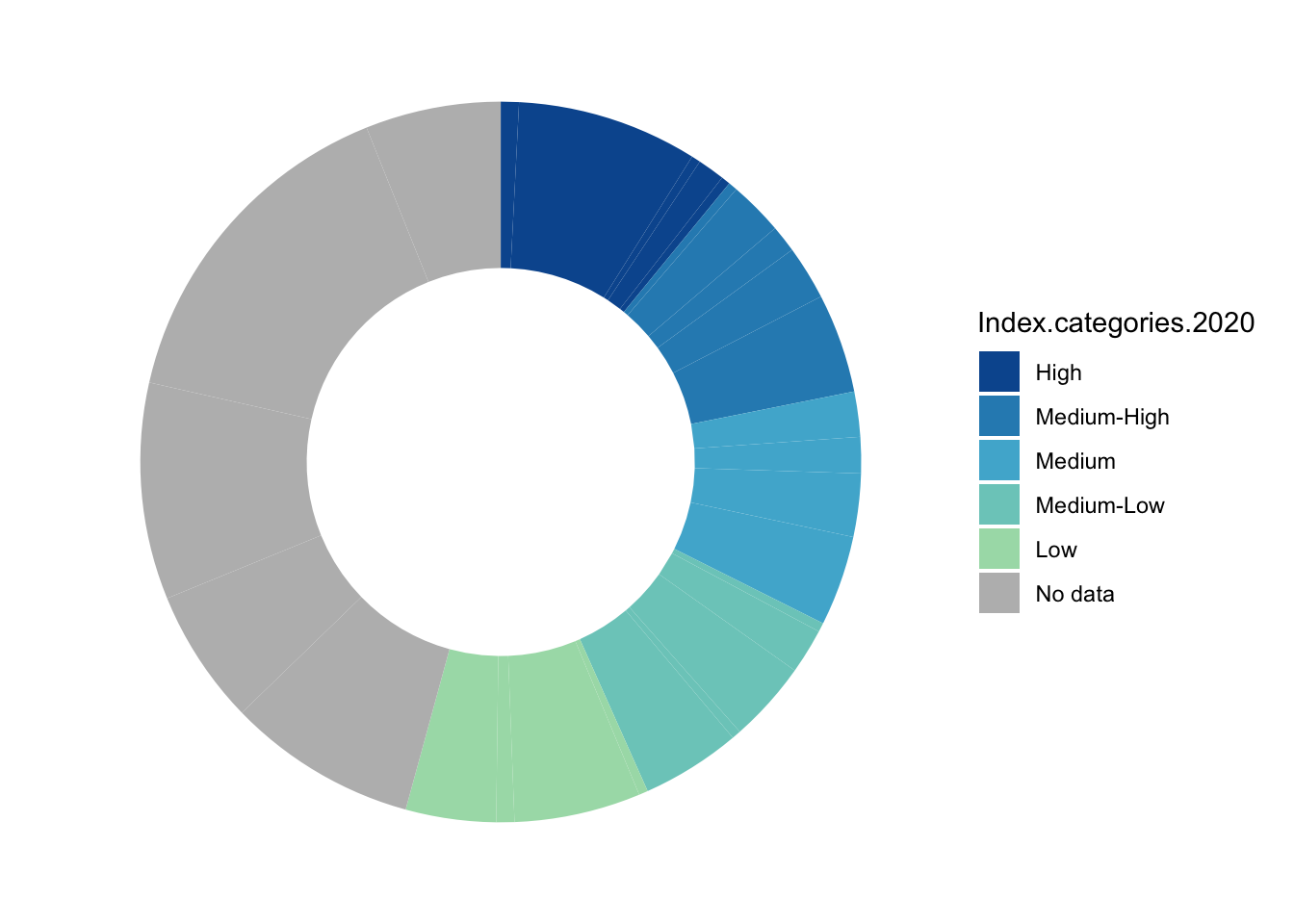
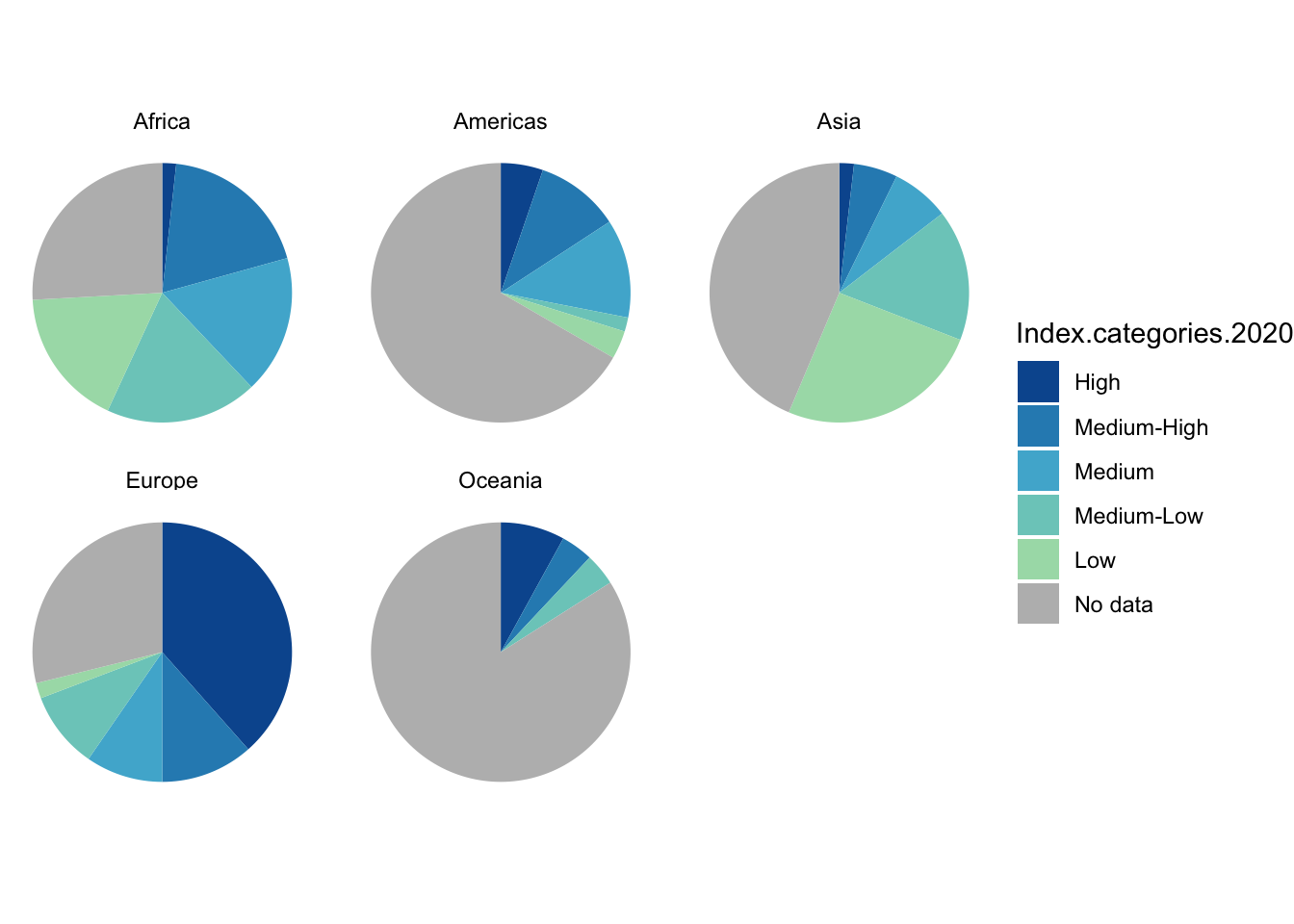
1.5.2 Add a variable: Small multiples
- It is very difficult - and likely inadvisable - to try to visualize an additional variable inside a basic pie chart.
- Instead, if you have a third categorical variable that relates to the data in the pie chart, you could try creating a separate pie chart for each category in that variable. we call that technique using “small multiples.” Small multiples are actually useful for a variety of visualizations, especially if the visualization is already complex and you don’t want to add to the complexity by including an additional variable.
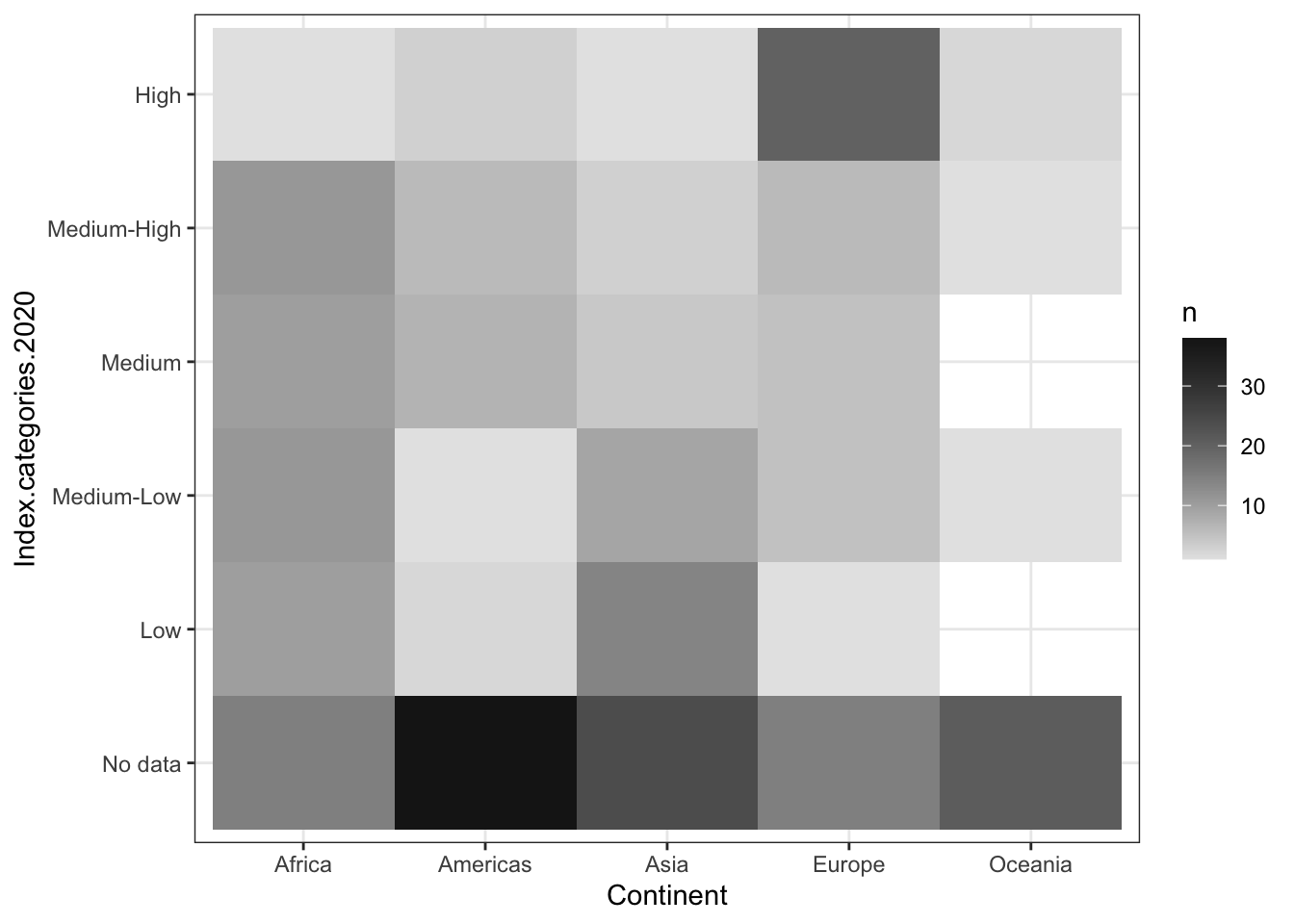
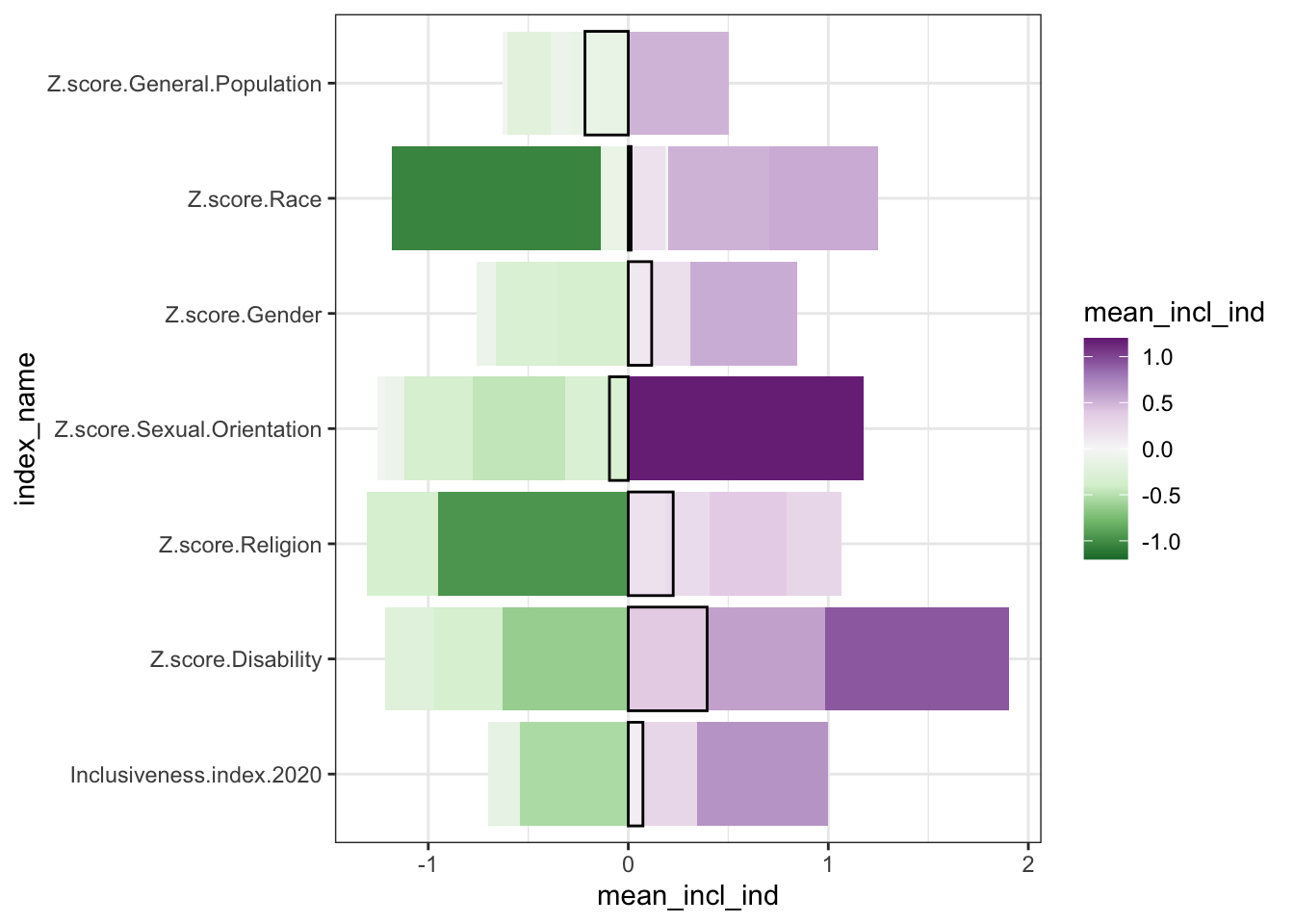
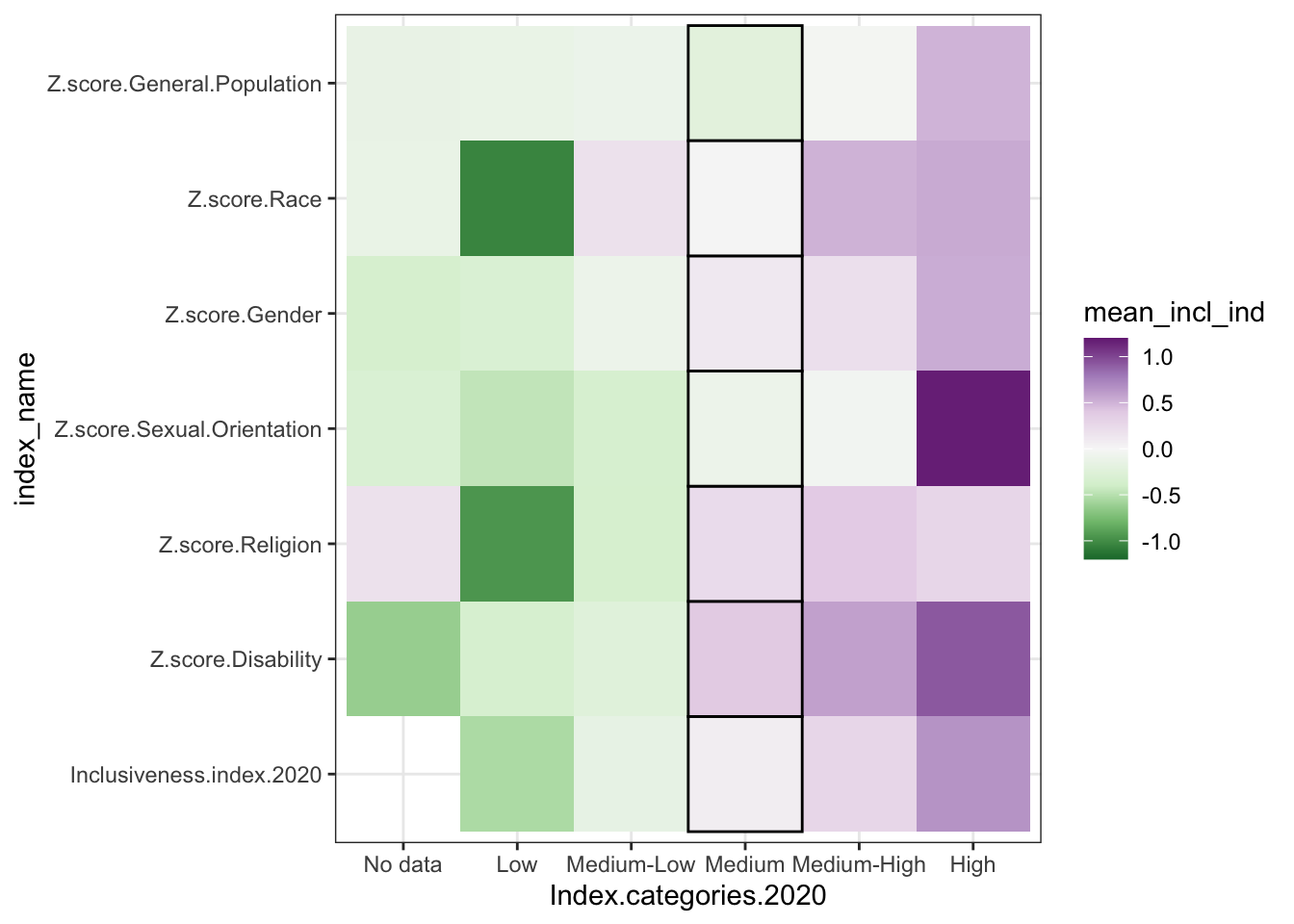
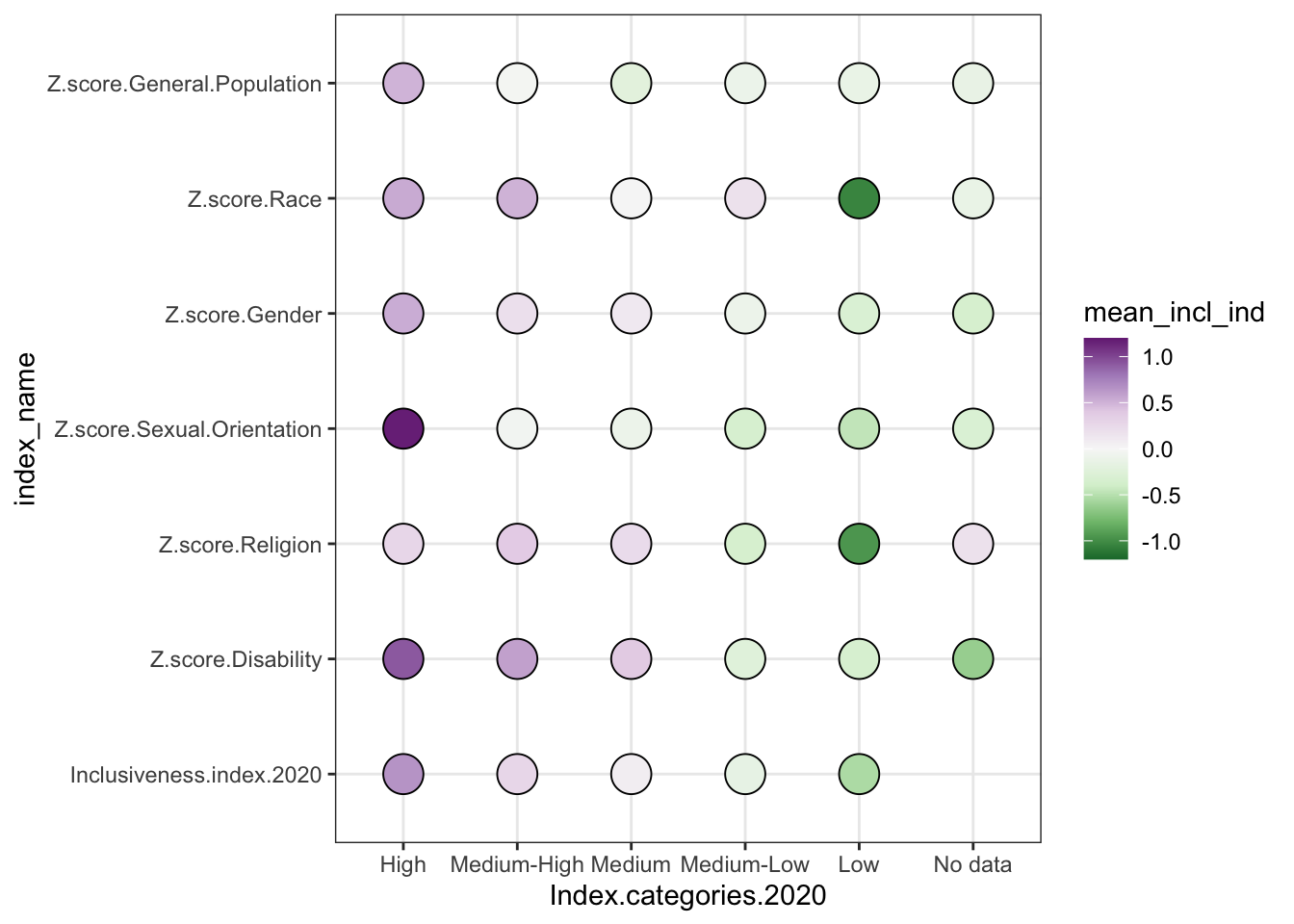
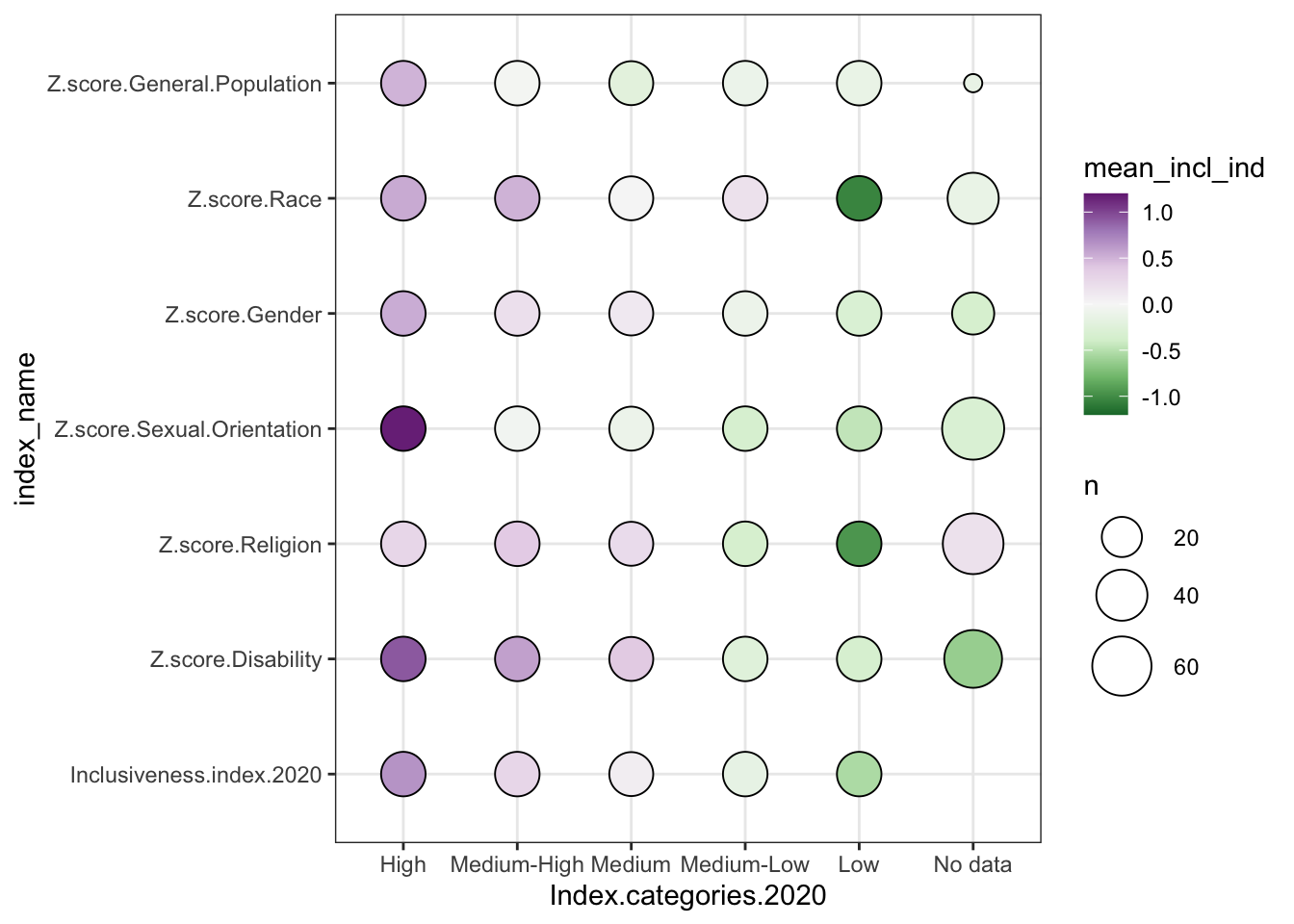
1.6 Heat Map
- two categorical variables and a numerical variable
- sort of like a stacked bar chart, but instead of showing the numerical variable as the size of the bar segment, you show it as a change in color.
- for example, longer segments -> darker colors in the grid
- bonus - no moving baseline problem
- problem - still hard to precisely compare values because just trying to compare color shades
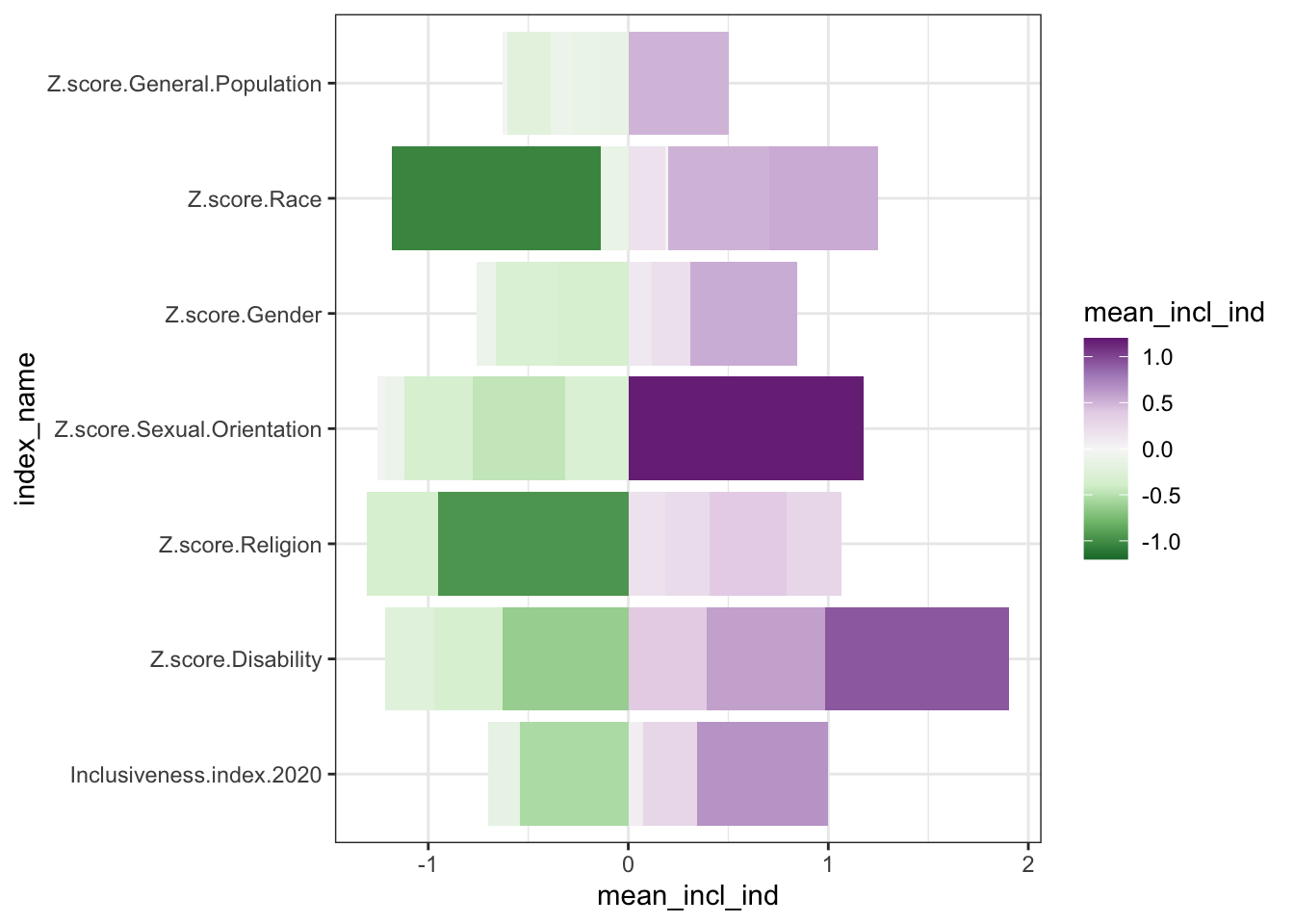
 * additional bonus, though - possibly better for negative values, since it can be
hard to represent negative values in a stacked bar where totals matter, or where
it doesn’t make sense to be adding the data together at all
* order only stays consistent if you are using all positive numbers; if there are
negative values, those get pulled out and appear under the axis.
* introduce diverging color
* additional bonus, though - possibly better for negative values, since it can be
hard to represent negative values in a stacked bar where totals matter, or where
it doesn’t make sense to be adding the data together at all
* order only stays consistent if you are using all positive numbers; if there are
negative values, those get pulled out and appear under the axis.
* introduce diverging color
1.7 Histogram
- Largely “one-variable” plots - that is, you pick a variable, and then the chart shows how the different values of that variable are distributed along the axis range
- most common example is the traditional bell curve
- goal is to look at the distribution of a numerical variable
- tend to look for a few common patterns - bell curve (with or without skew), pareto plot, bimodal distribution, etc.
- shape (and y axis values) will depend on binning, whether the numerical variable is an integer or floating point, etc.
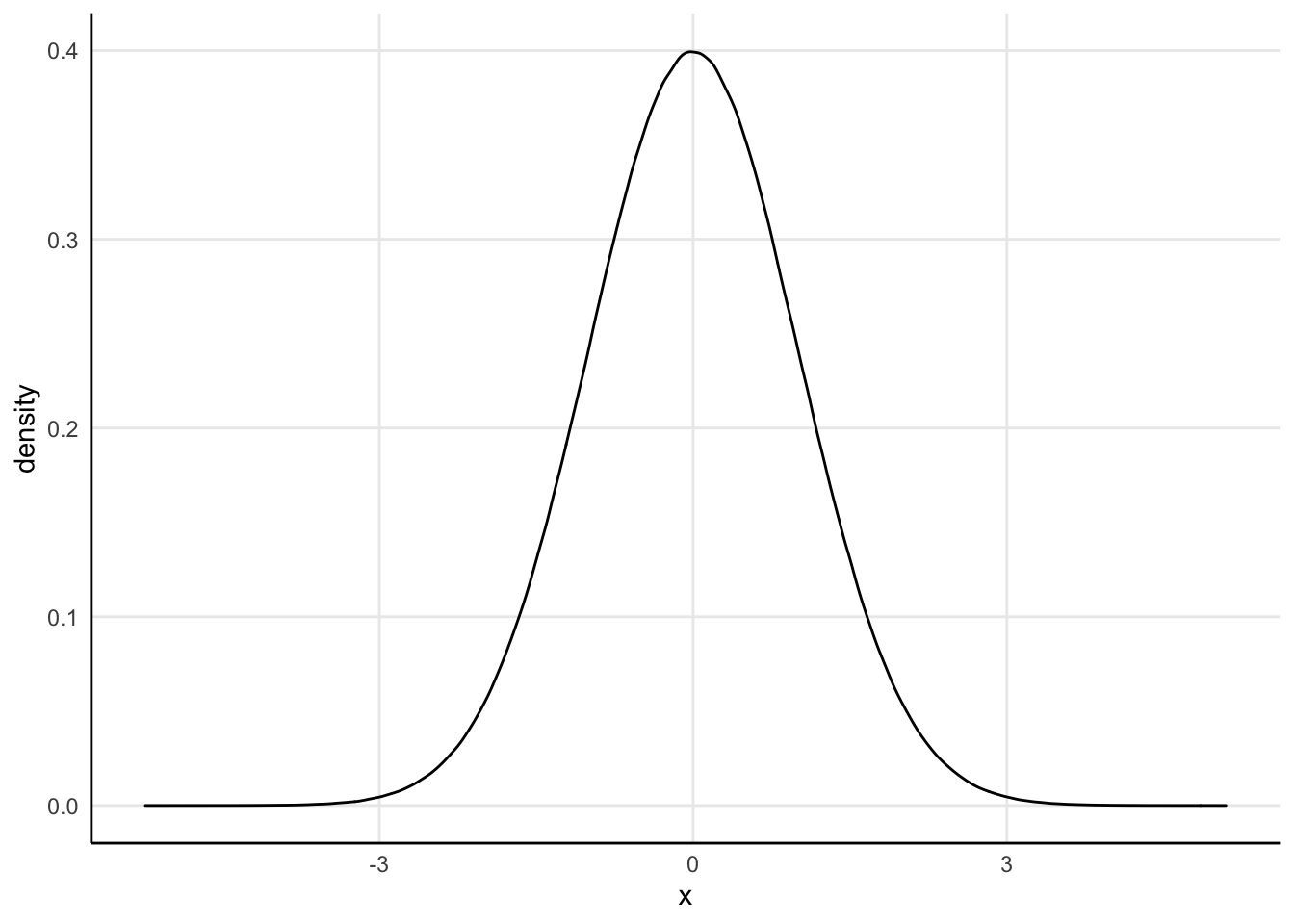
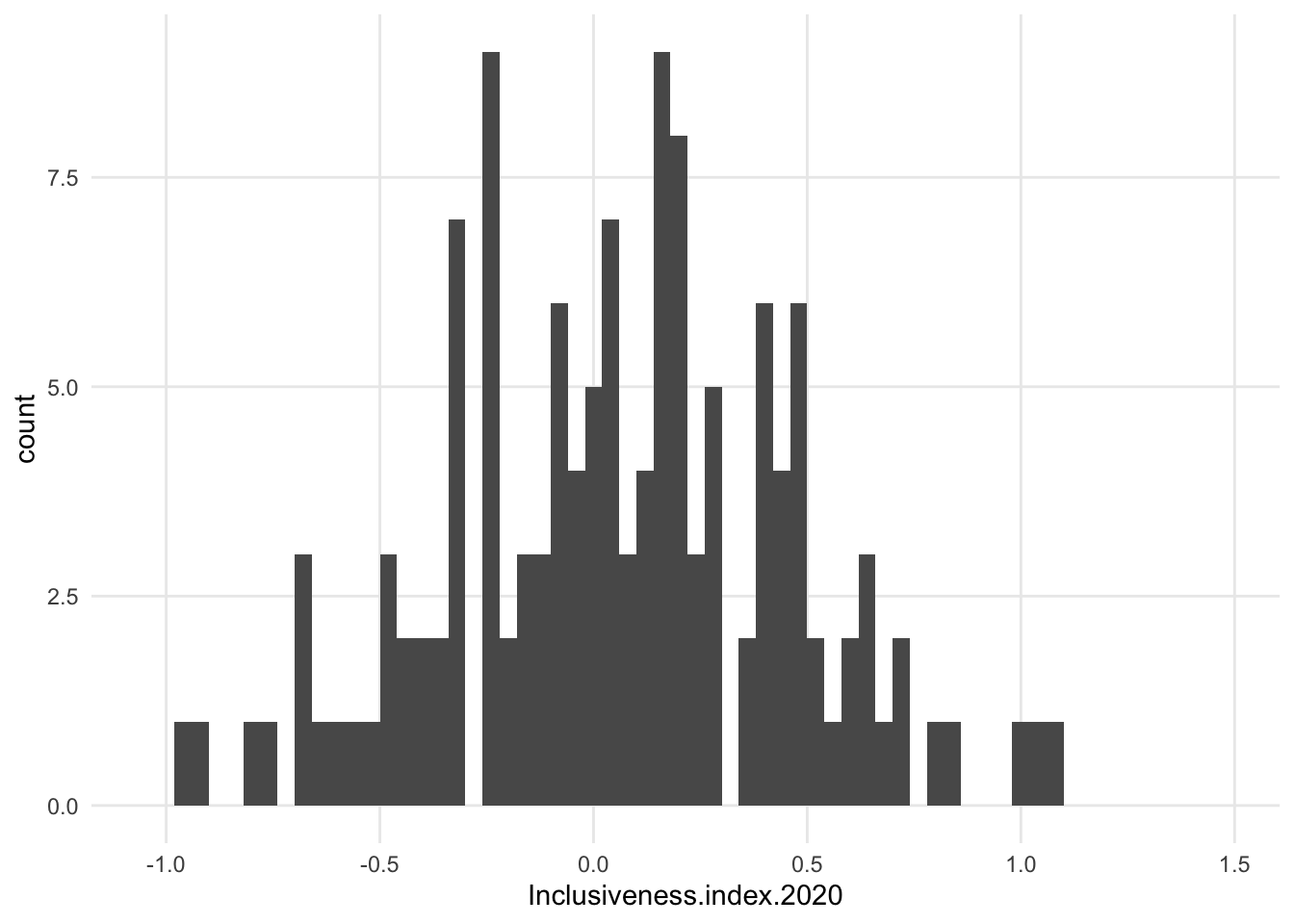
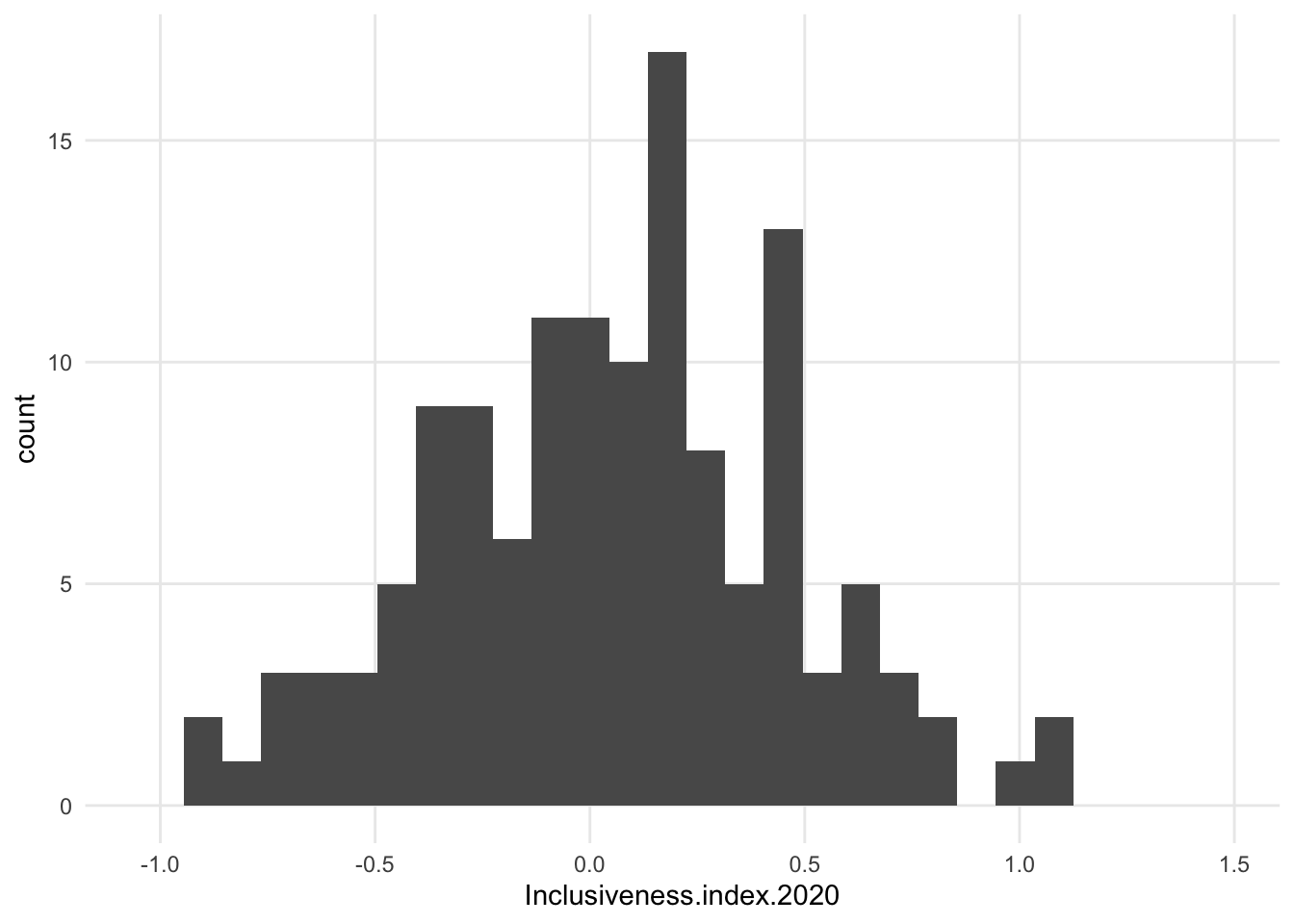
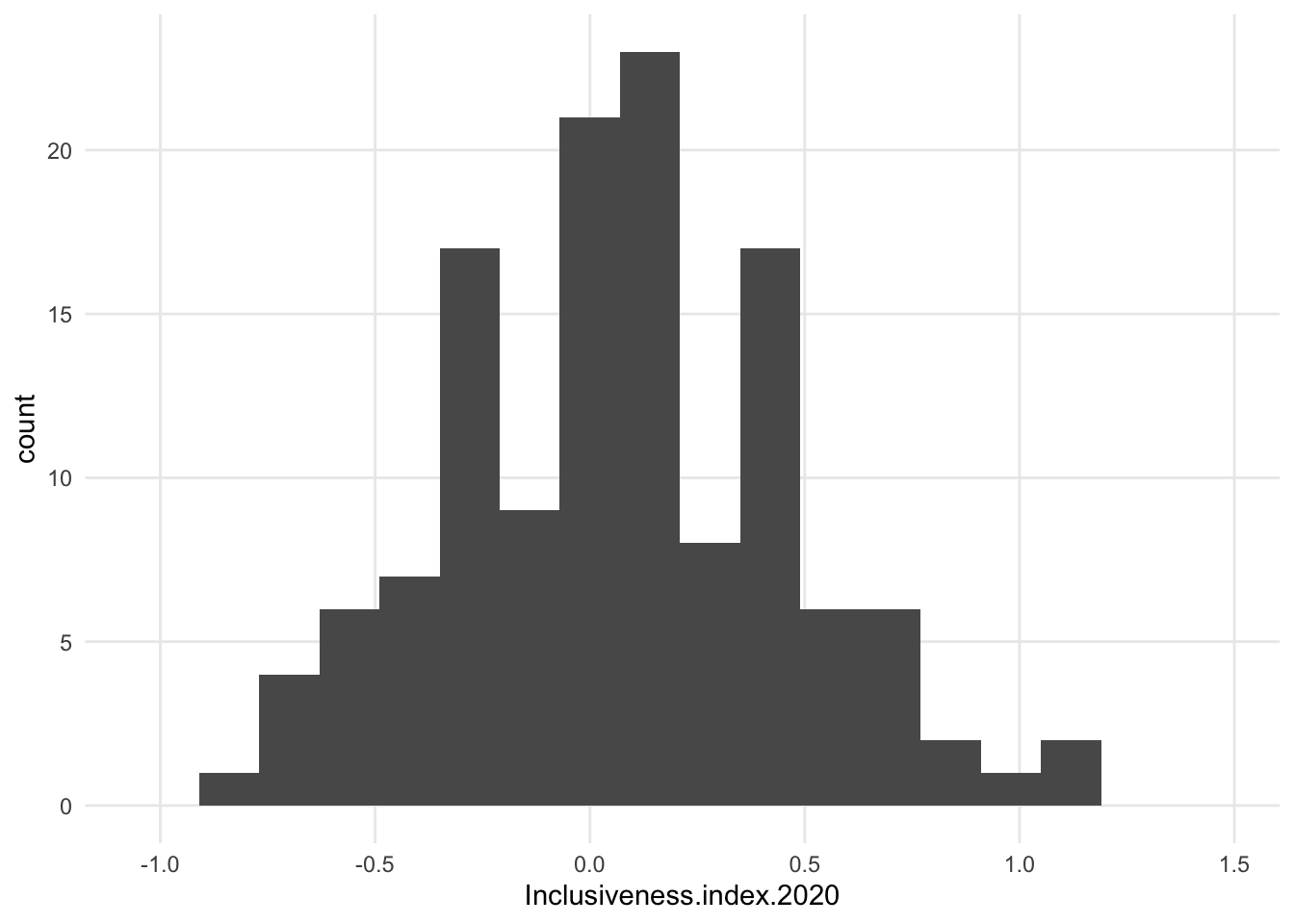
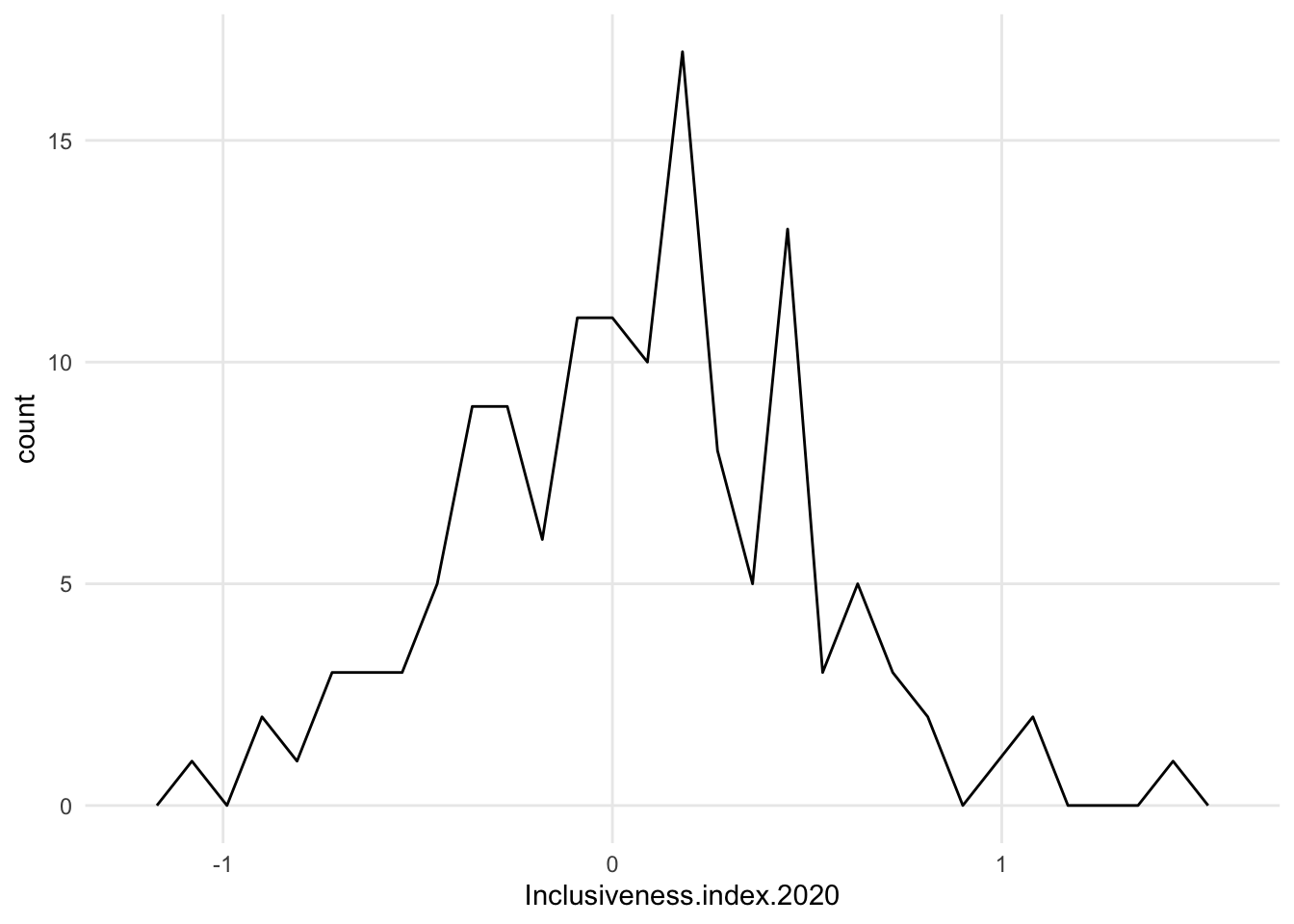
1.7.1 Variations
- a bunch of variations, some of which continue to use the x axis as a baseline and others center around an arbitrary value
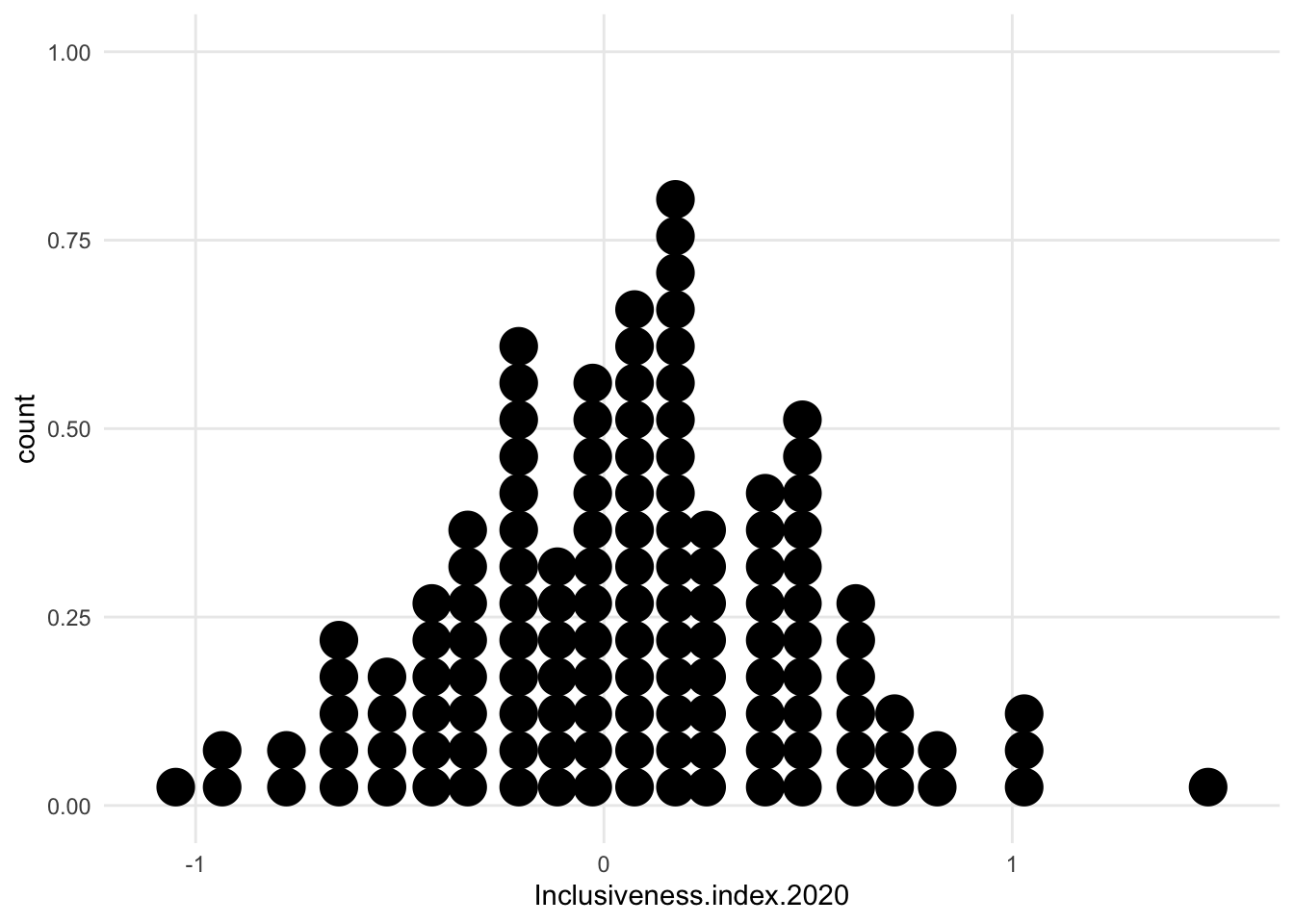
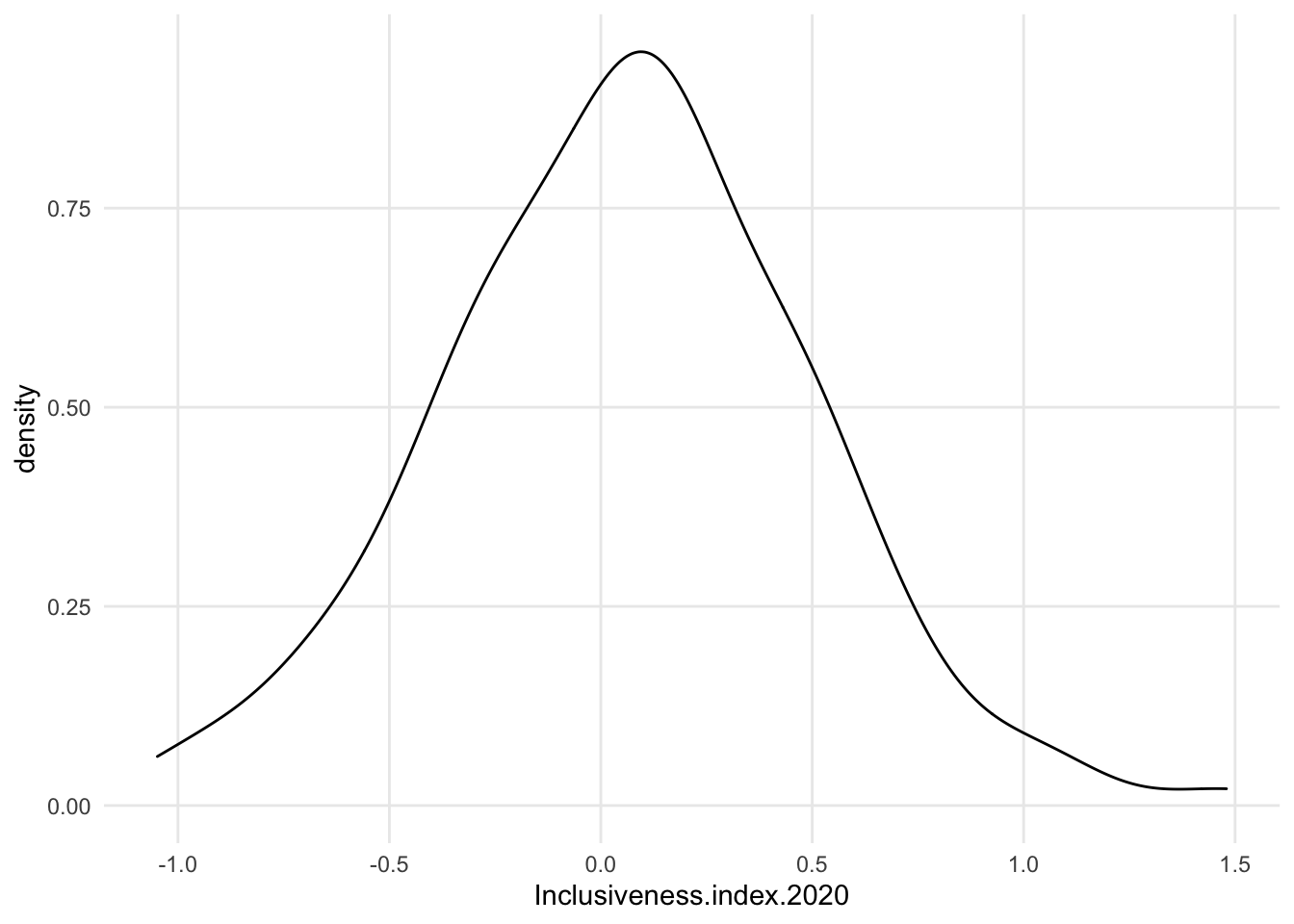
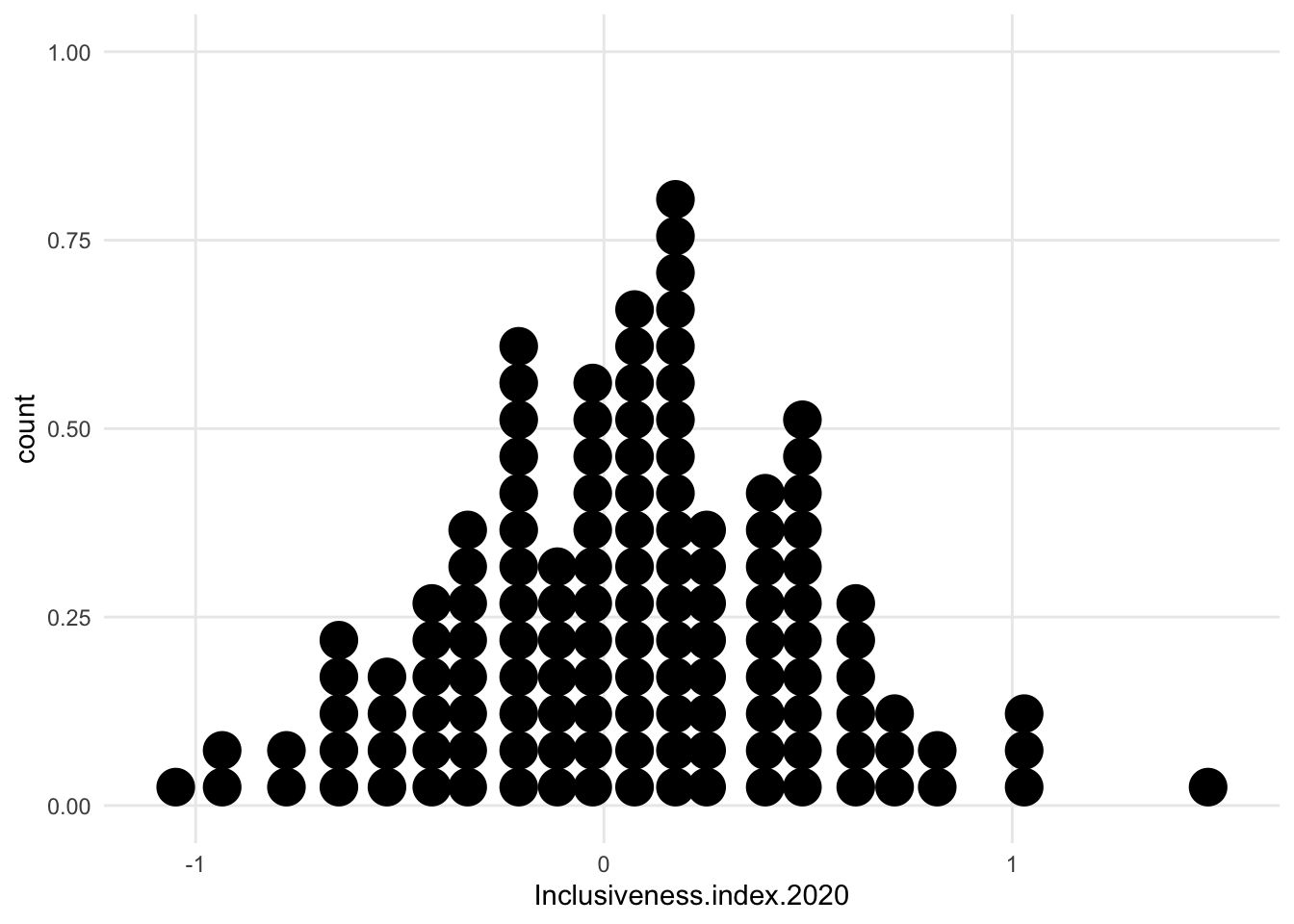
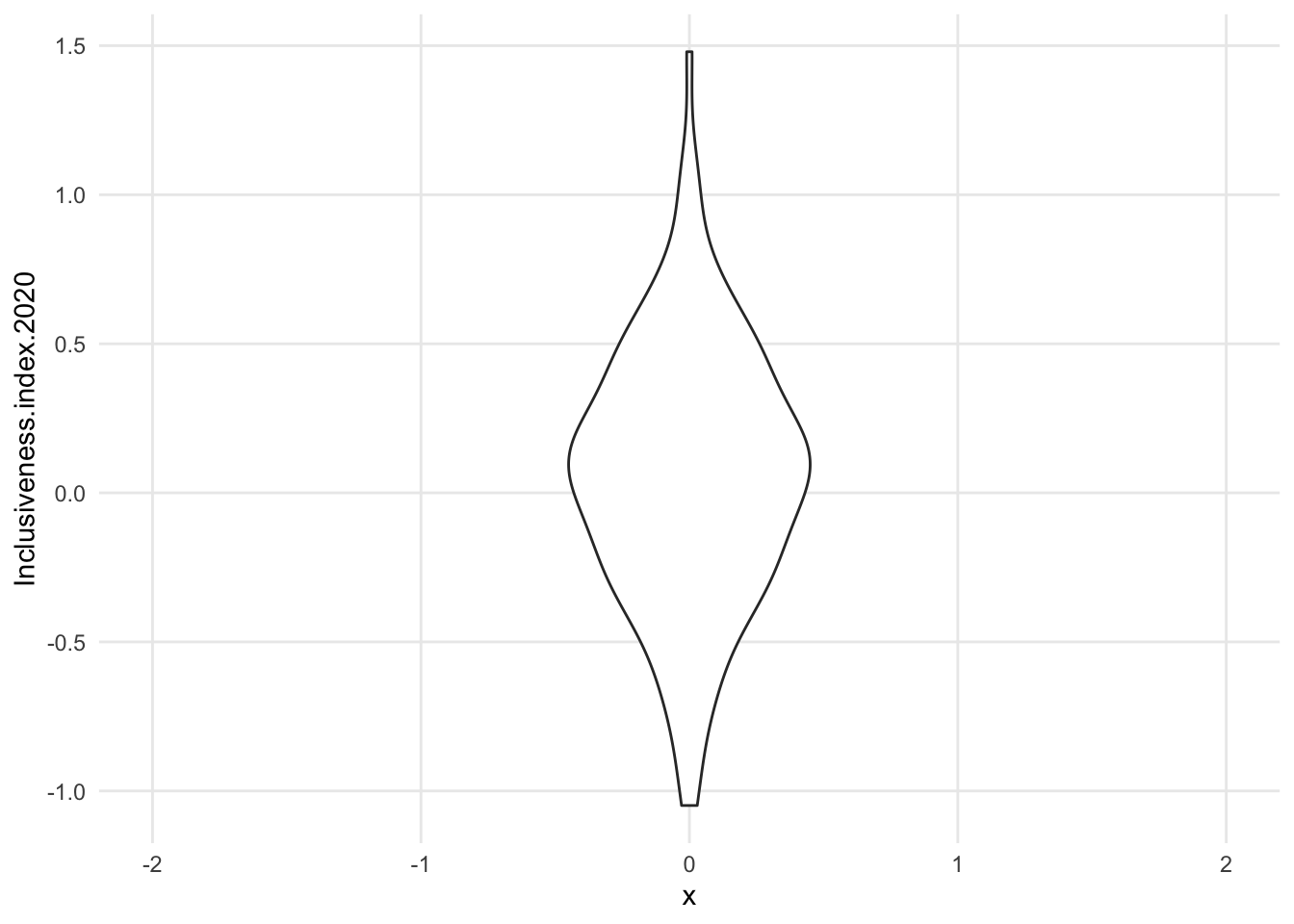
1.7.1.3 Density
- intensely smoothed
- algorithm *kernal density estimation)
- area under the curve adds up 1, so the y axis is just fractions of that, not really meaningful
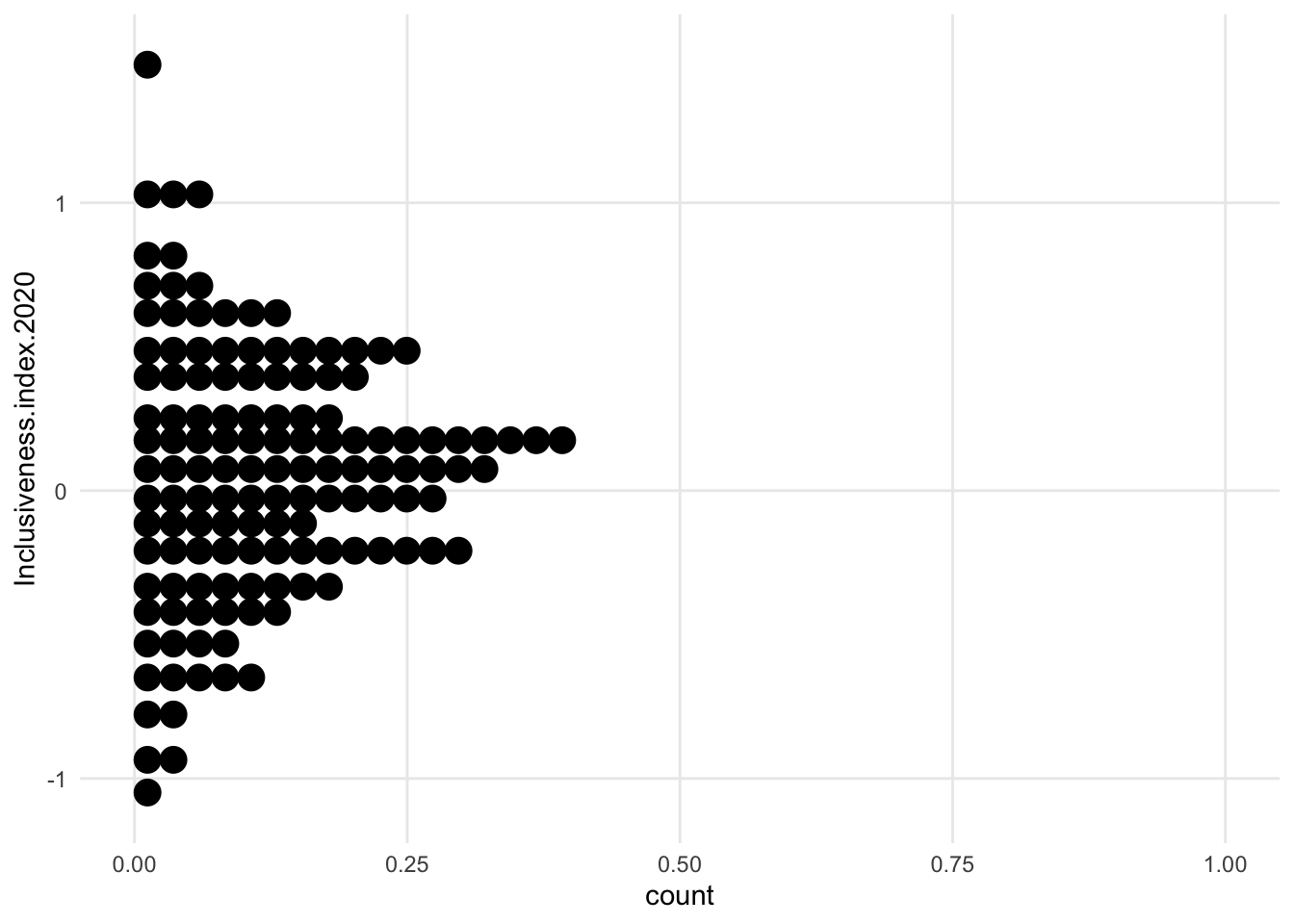
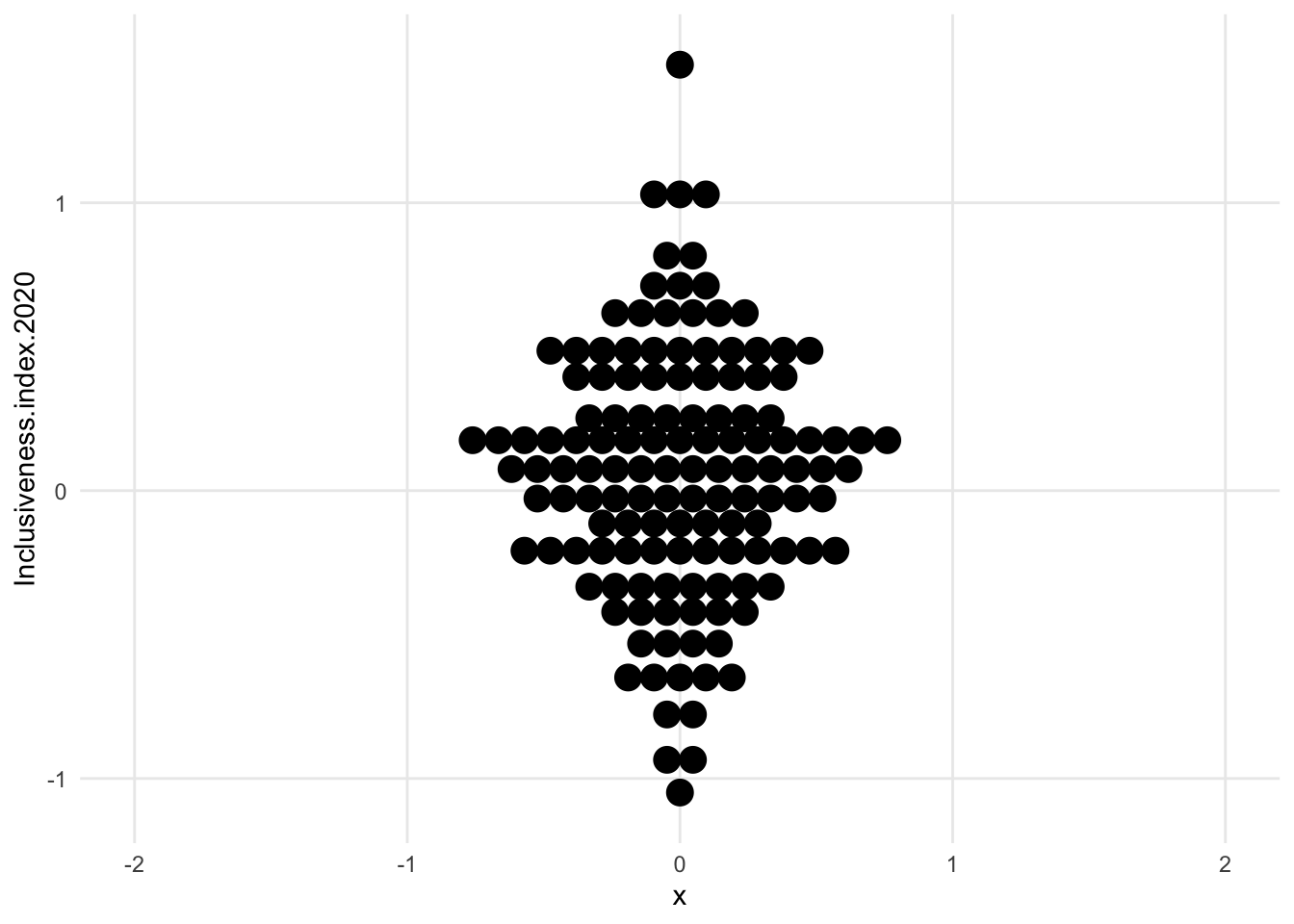
1.7.1.4 Centered dot plot / Bee swarm
- first of the “centered” distribution charts
- the variable we’re exploring is not on the x axis anymore. It’s now vertical, and instead of having a flat side, the shape is centered on an arbitrary x value (here, 0)
- bee swarm is like our previous dot plot, just turned and centered
- concerns - maybe harder to estimate change when things are centered? we may unintentionally only look at half of the shape and make changes seem smaller
1.7.2 Add a variable: Separate groups on x axis
- because the data have been pulled away from the axis, we can now combine multiple distributions in the same chart.
- could split the data into subsets and show one distribution per subset
- could explore the distributions of different variables in the data, if they are all comparable
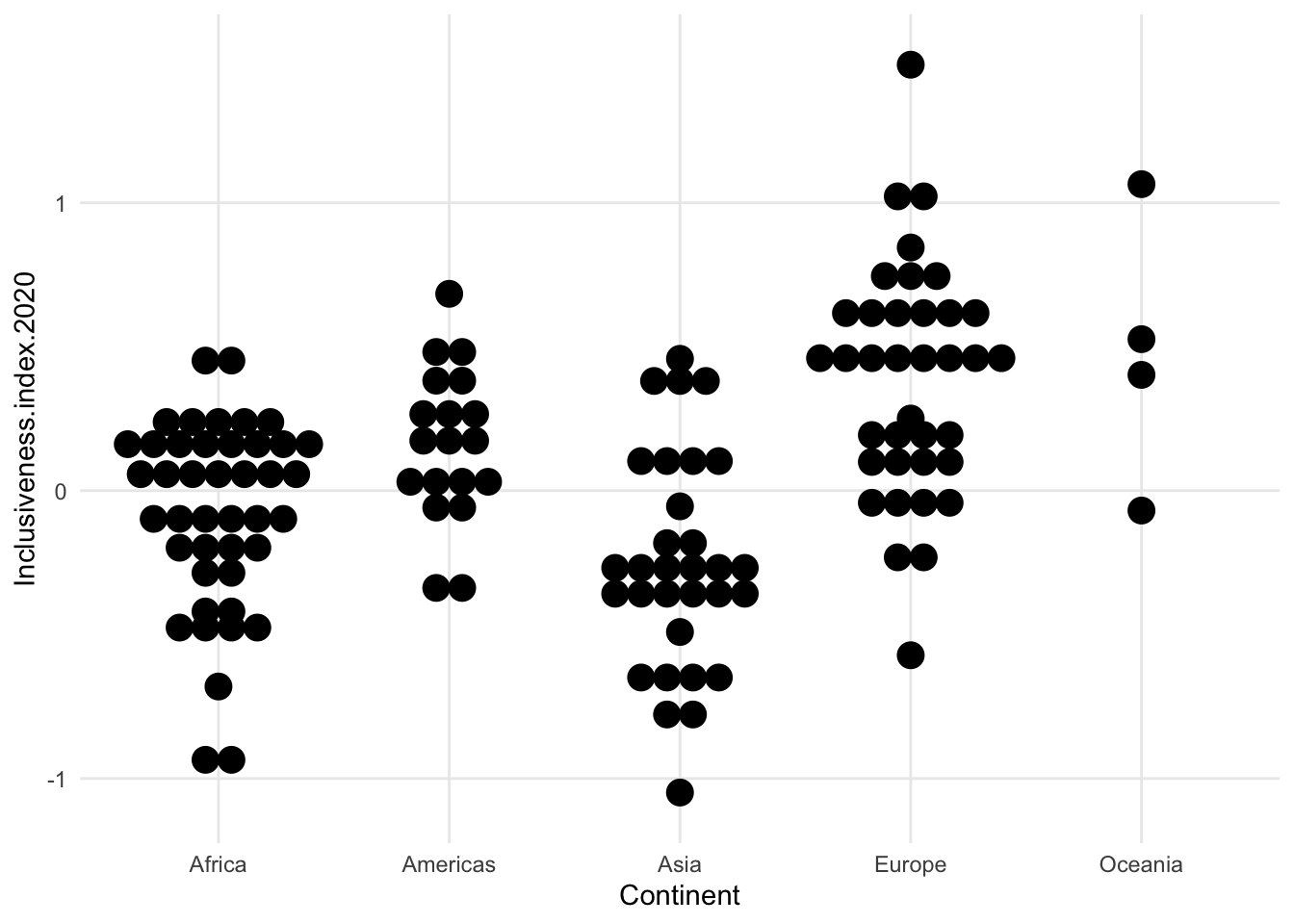
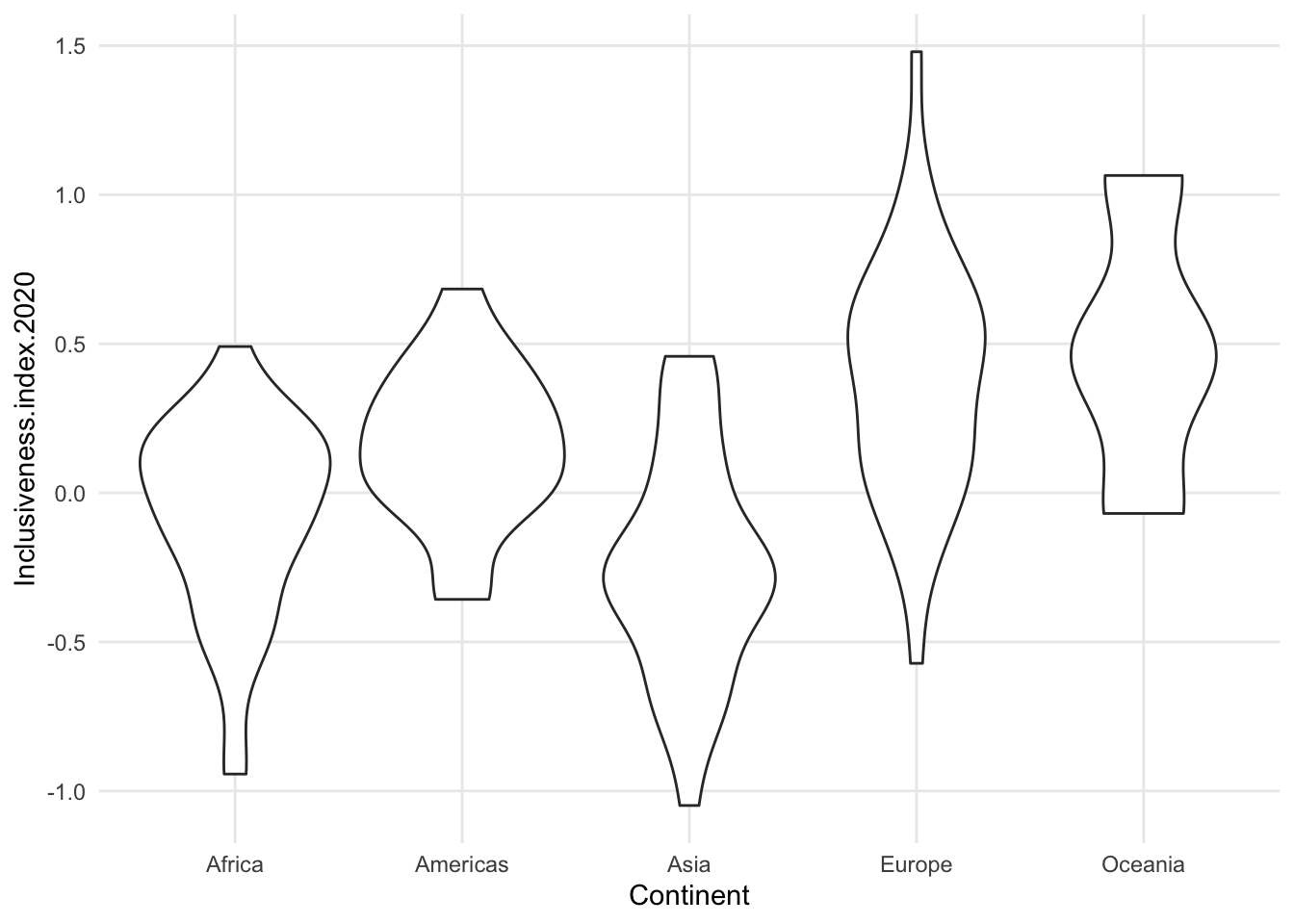
- compare violin to dotplot for Oceania - one looks like there’s a tiny amount of data, the other looks about the same as the others.
- can combine some of these summary plots with a scatterplot of the actual data
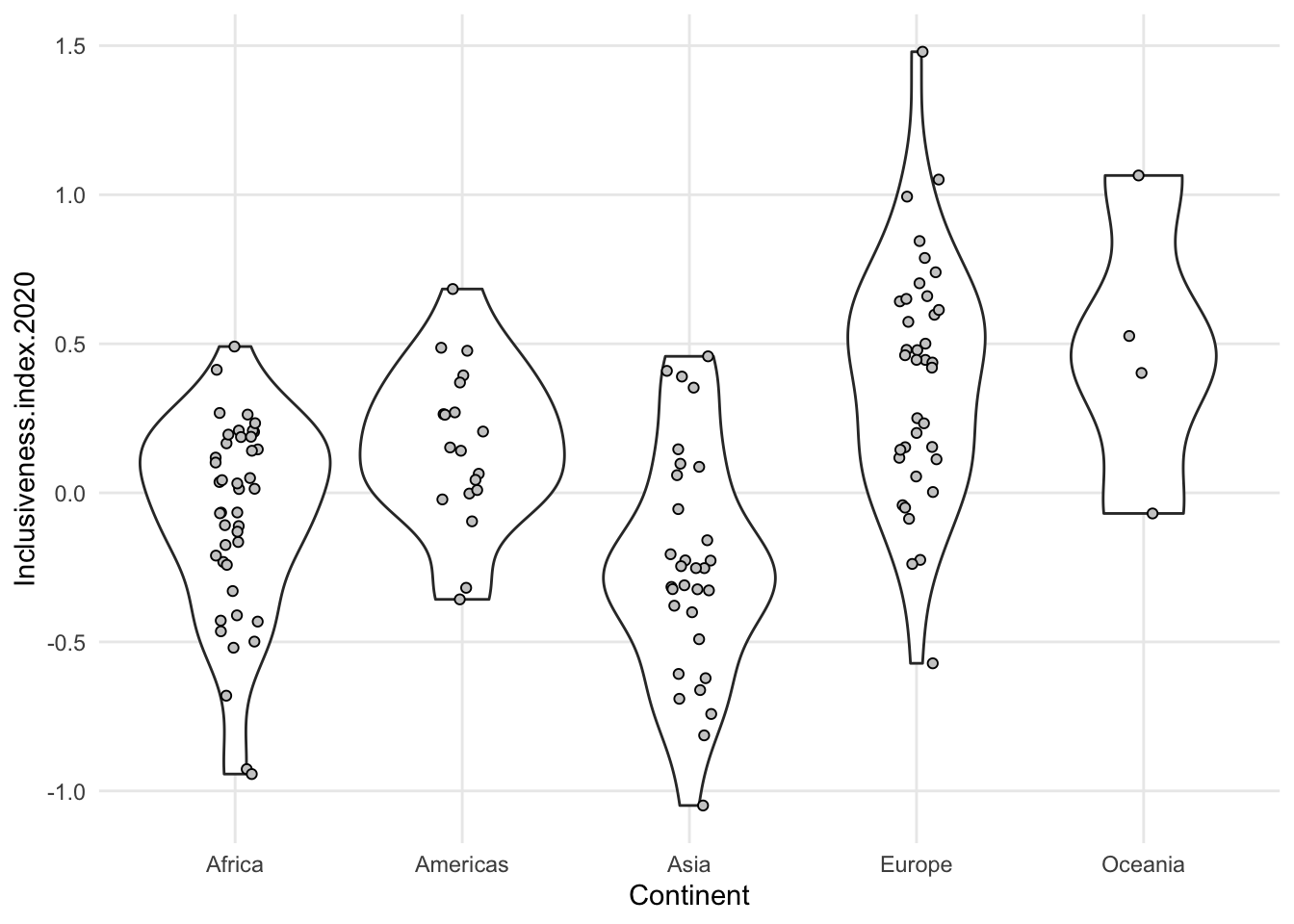
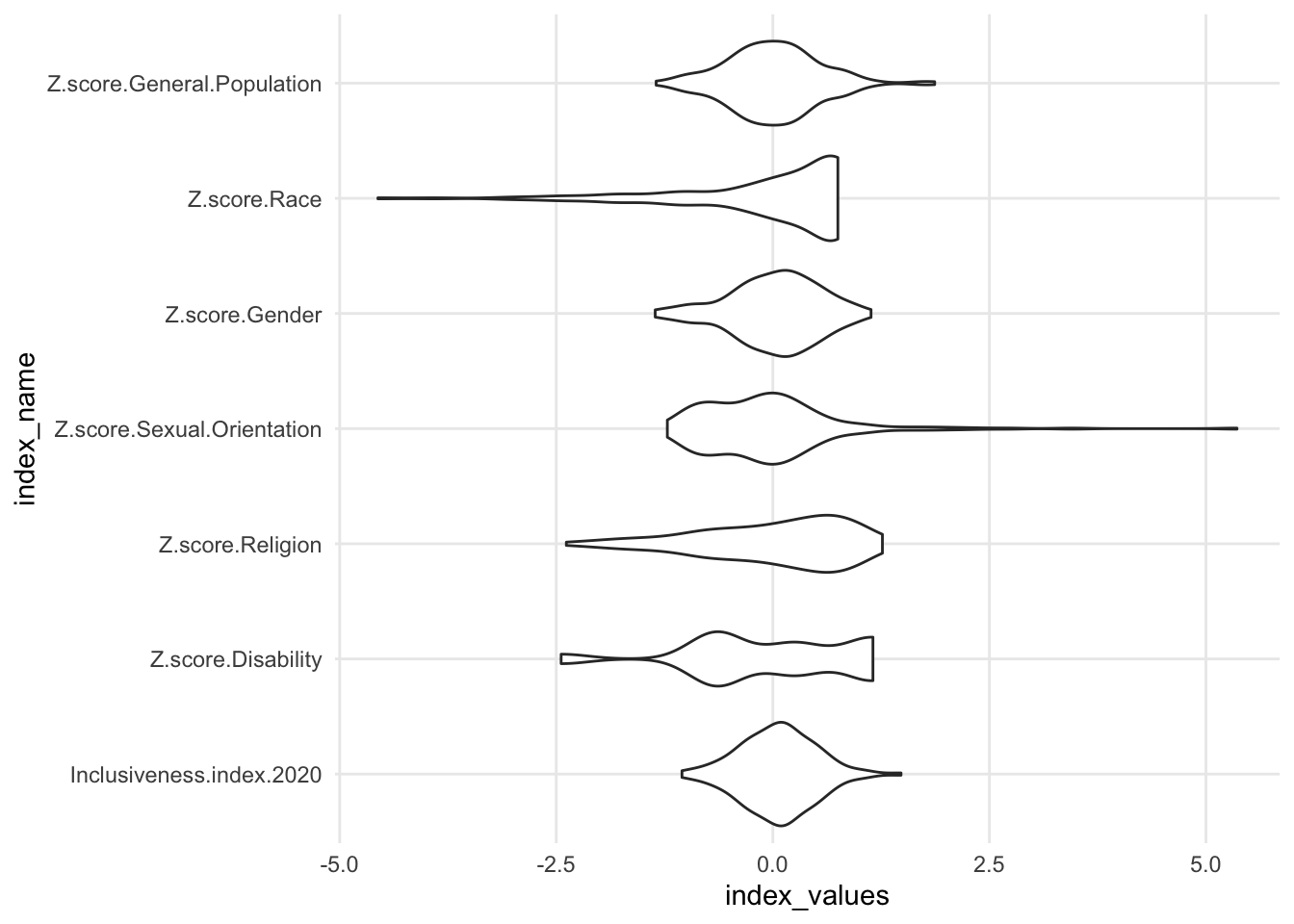
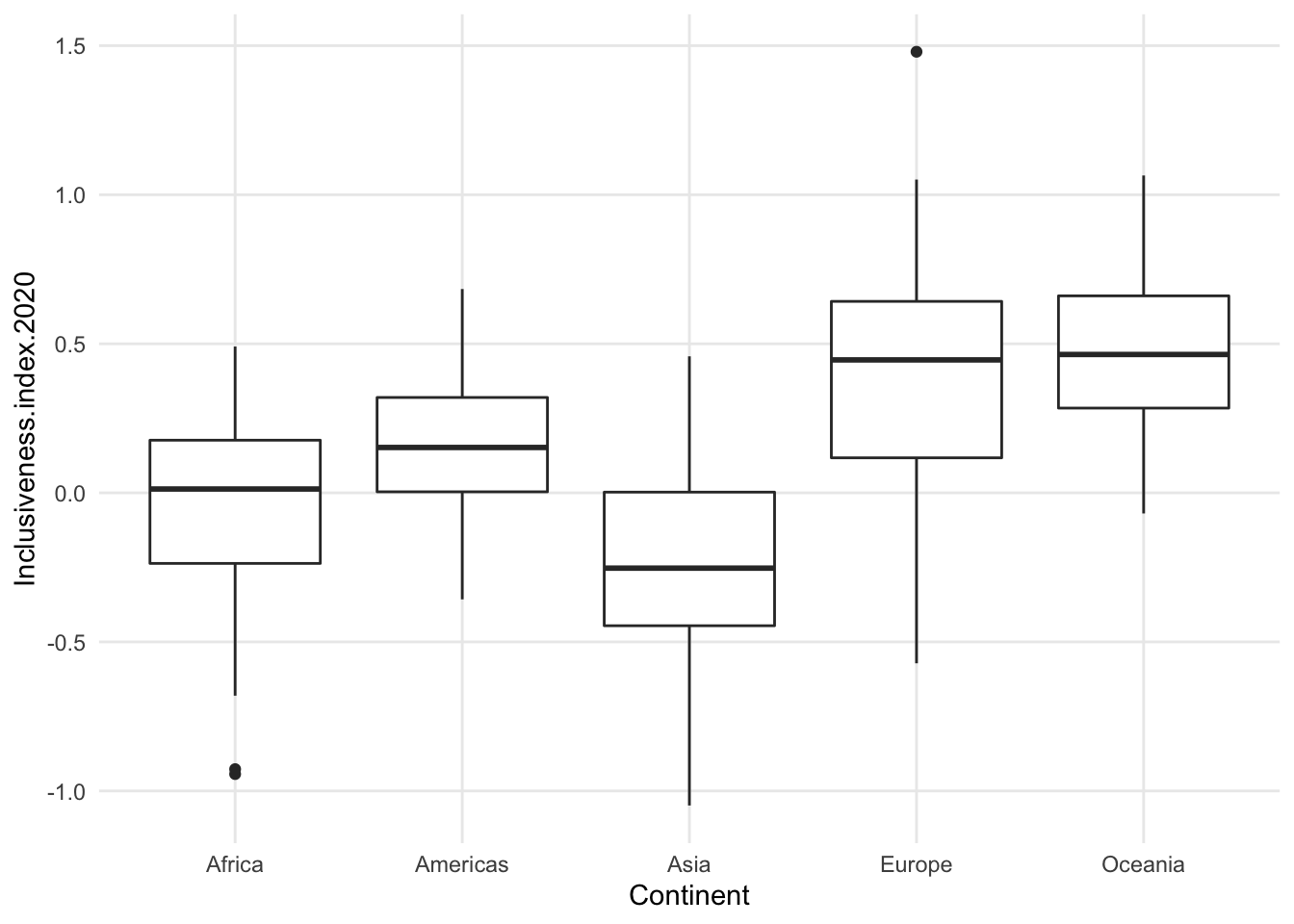
1.7.3 Add a variable: Separate groups with color
- when using the on-the-axis versions, can be hard to add a third variable. they will all compete for space on the same axis.
- technically can add color to a histogram to get counts for a third variable, like a stacked bar chart
- can be very hard to interpret
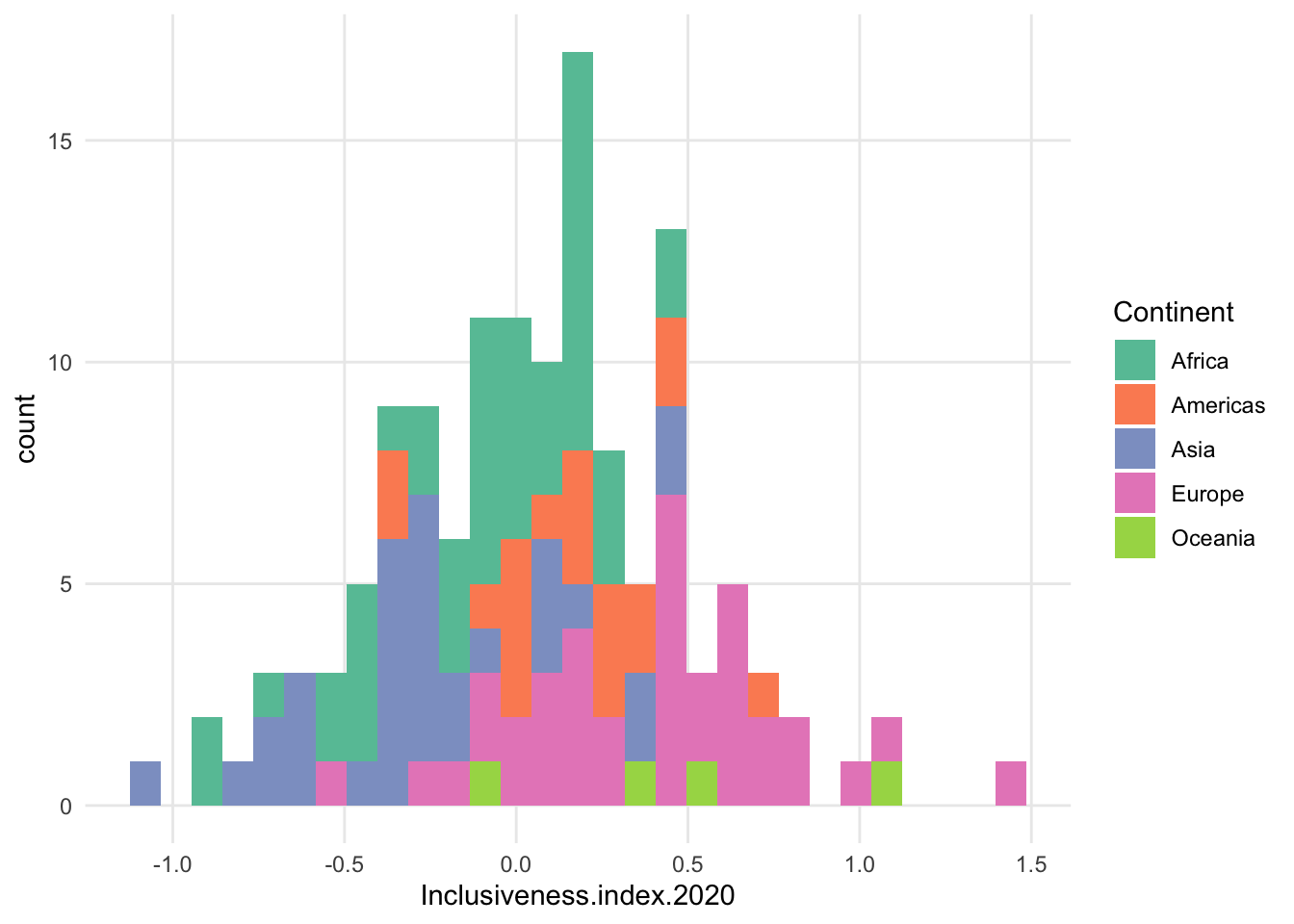
- grouped bar chart even worse
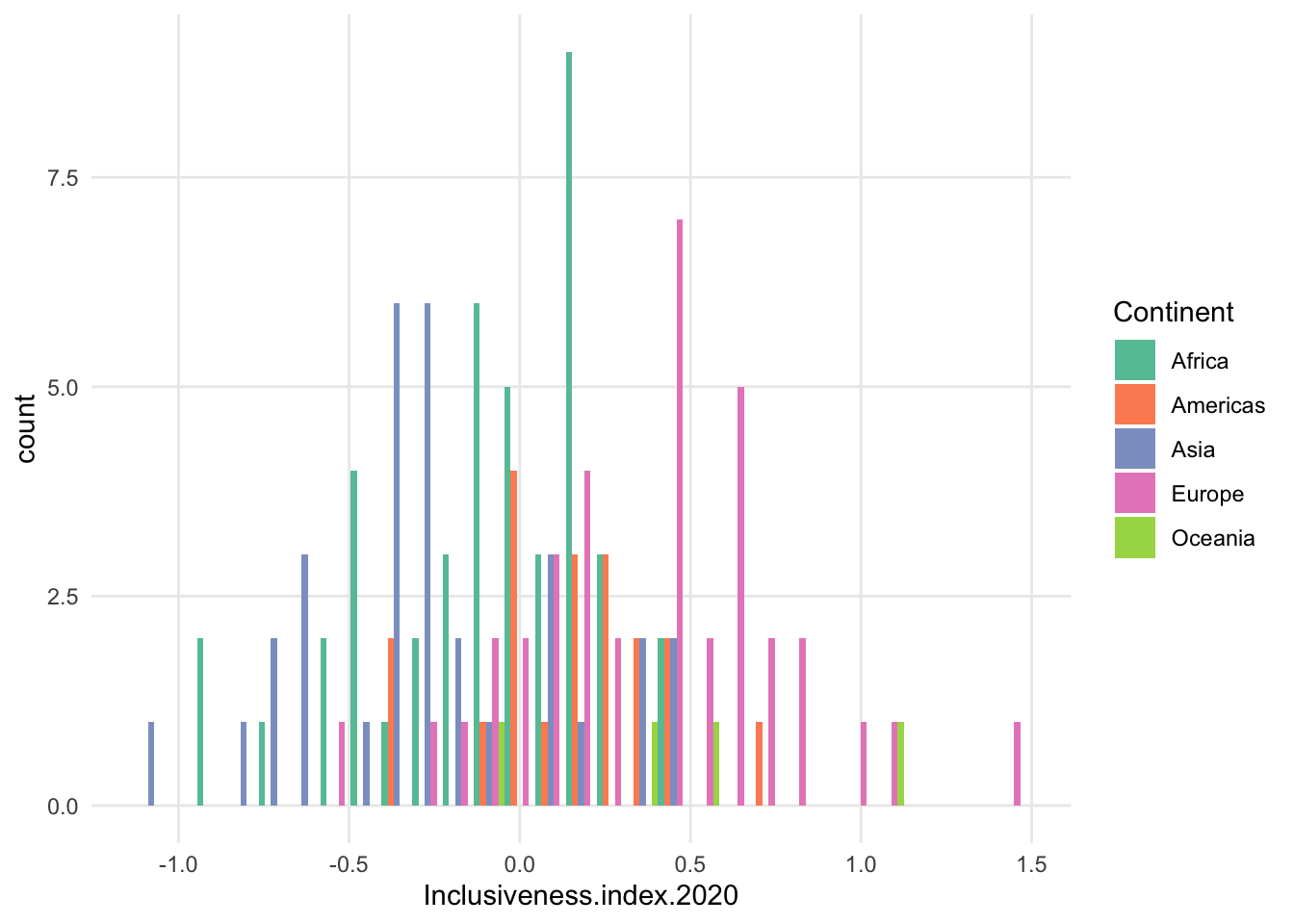
- freqpoly is a bit better, but can still be very choppy, and the fewer data points in a subset, the less smooth the patter will be
- maybe increase bin size?
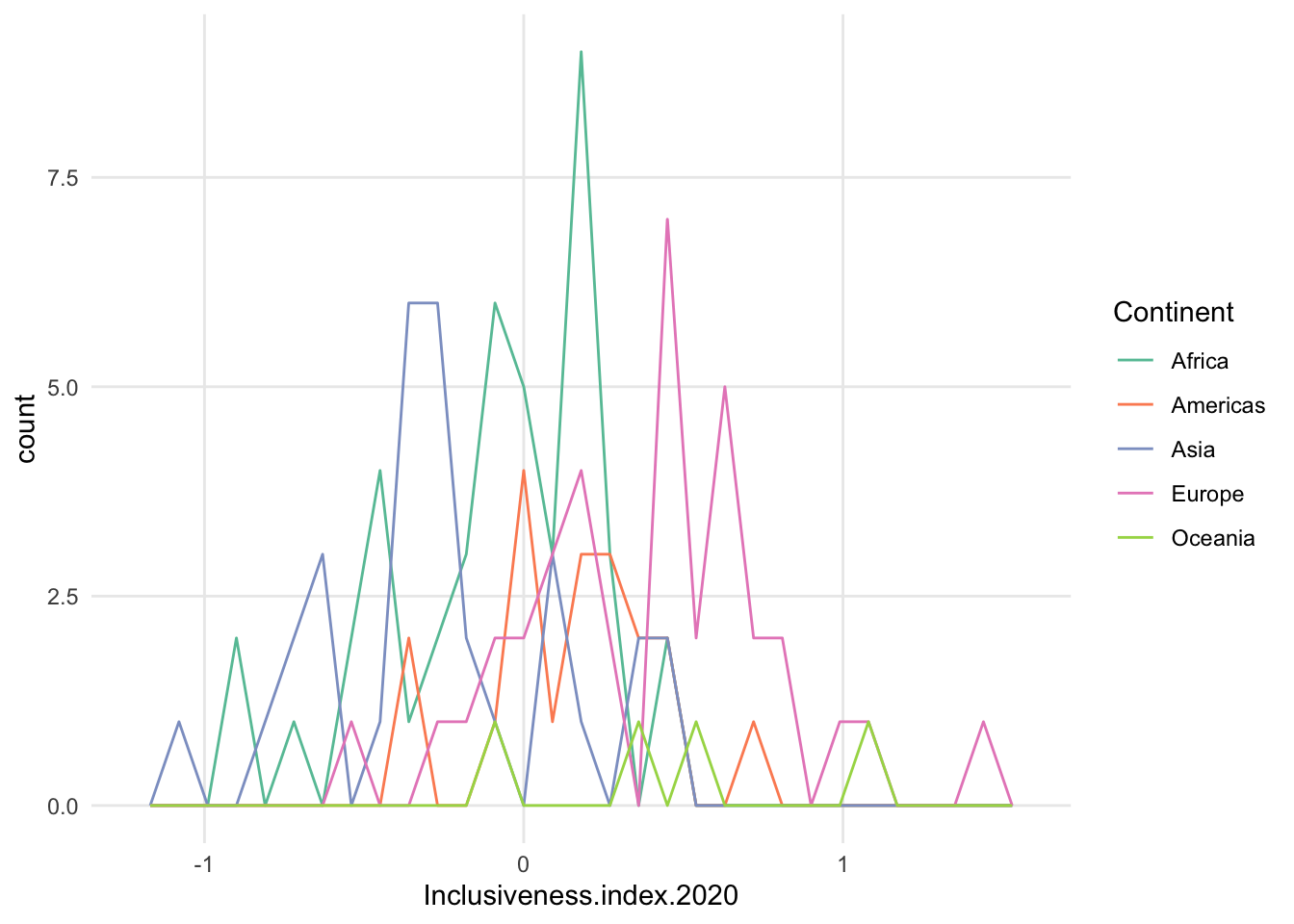
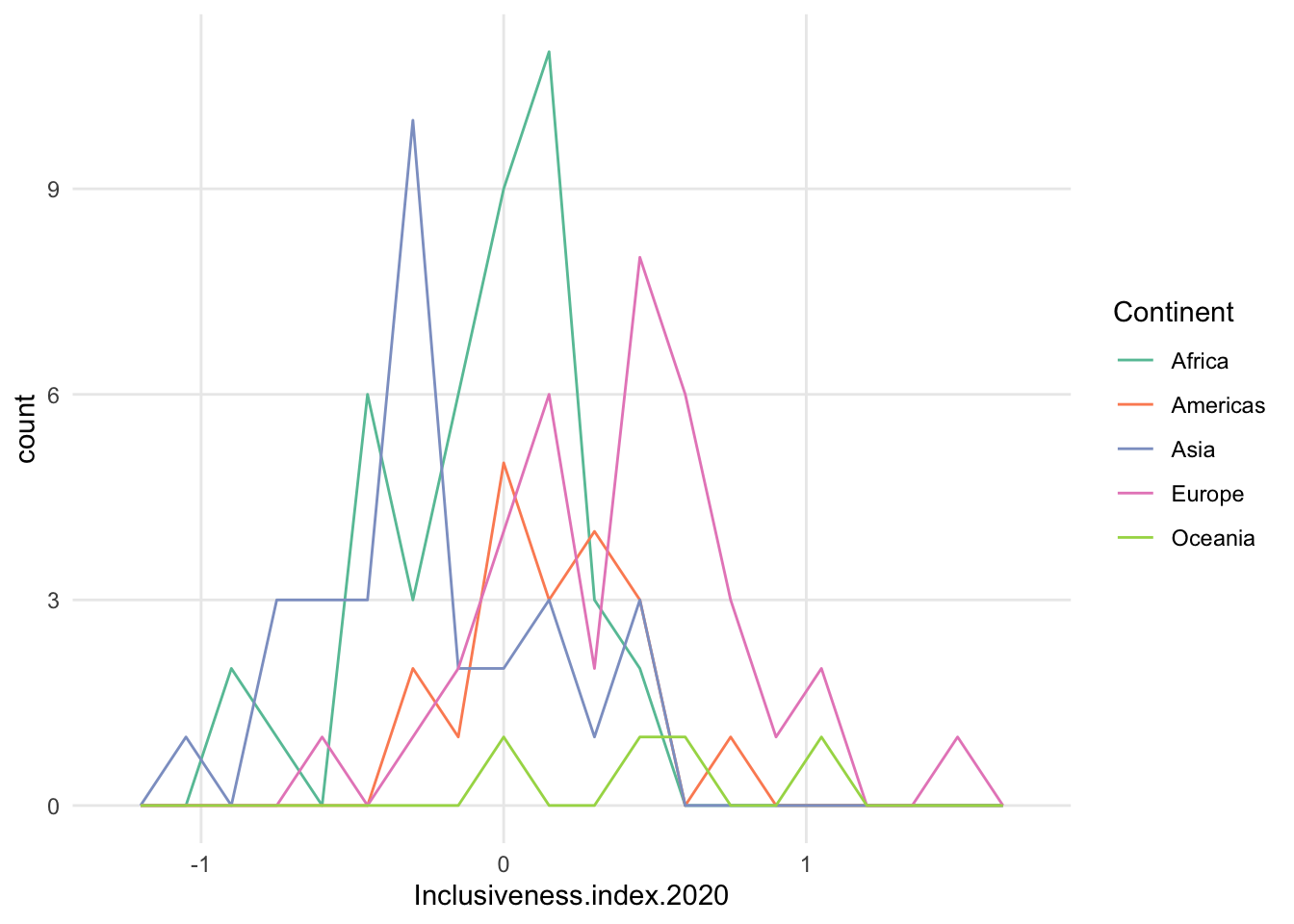
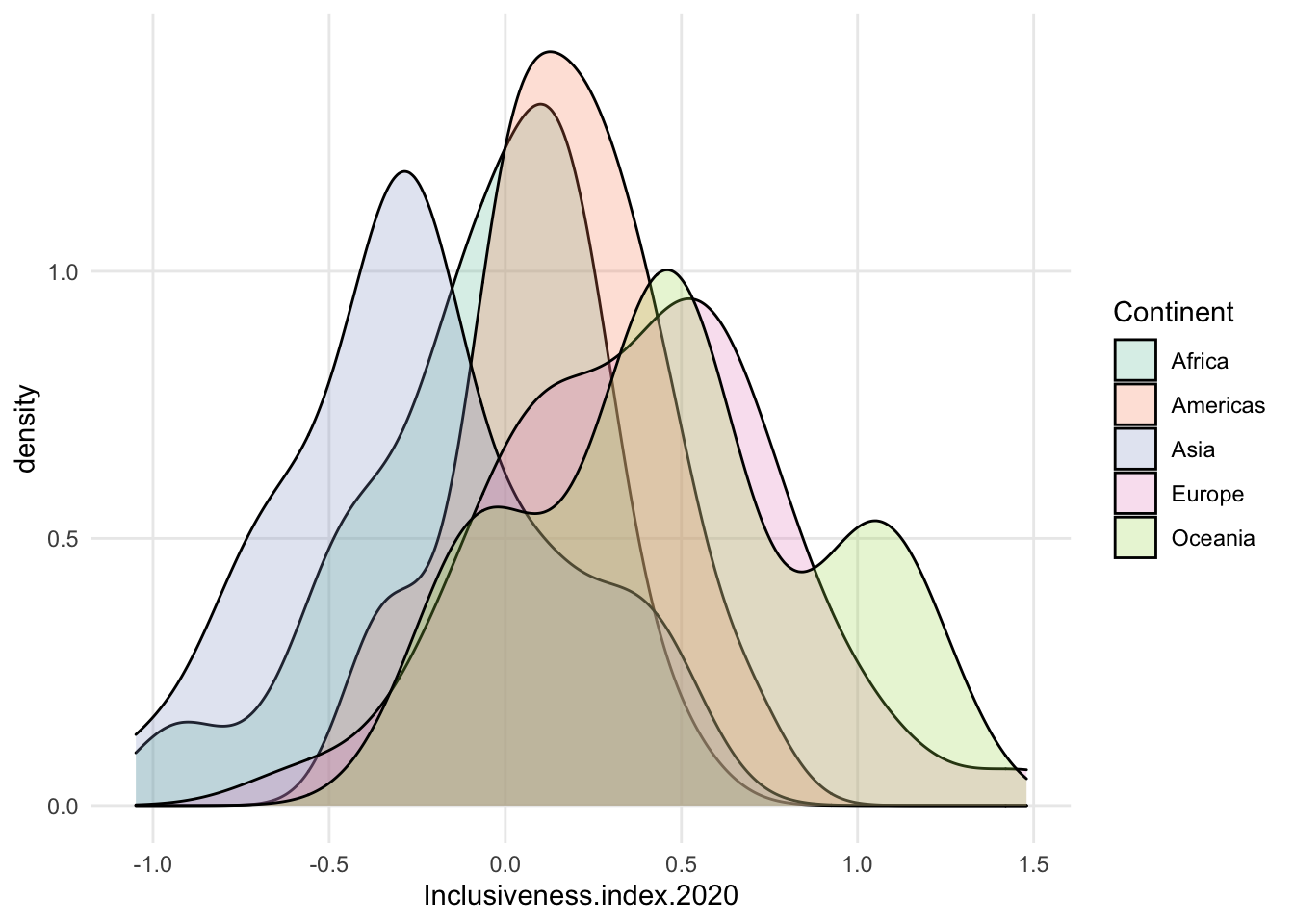
- possible exception is density. often see this because it smooths the data nicely.
- tend to see the density curves filled in with a mostly transparent color, instead of just coloring the lines.
- important to remember that the number of data points in each group could be very different. Each curve has a density value of 1 under the curvey, no matter how many data points went into the group.
- a high peak on a density curve doesn’t mean more data points at that point, necessarily. it means a high proportion of data in that range, within that particular subset.
- if counts are important, you could create a small multiple version of histograms.
- example: compare Africa and Americas below - density pretty close, histogram shows there are many more data points for Africa
- also, Oceania looks comparable, but really only has 4 data points
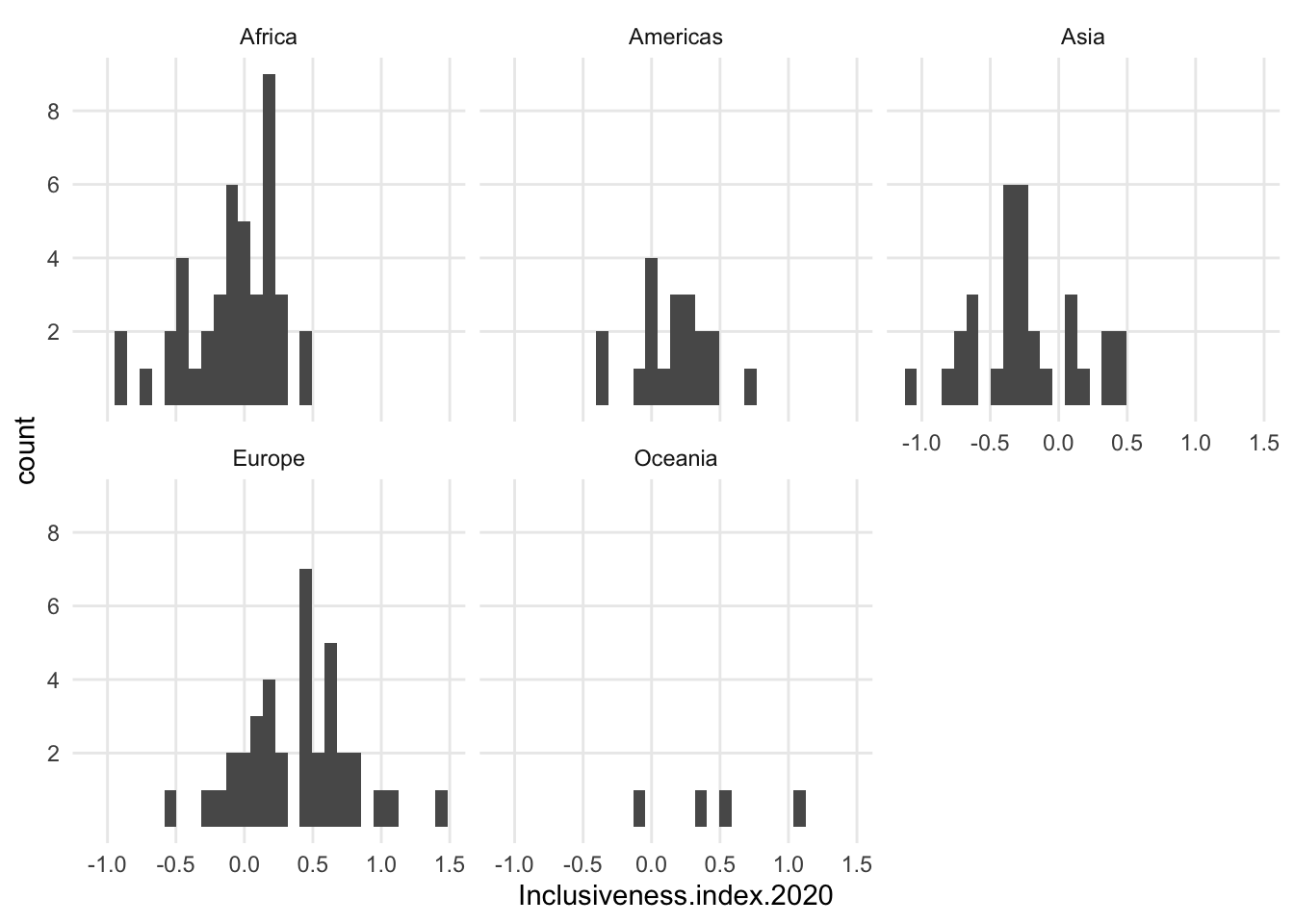
1.8 Maps
Won’t be dealing with maps much in this book, but here are two classic map types and how to read them
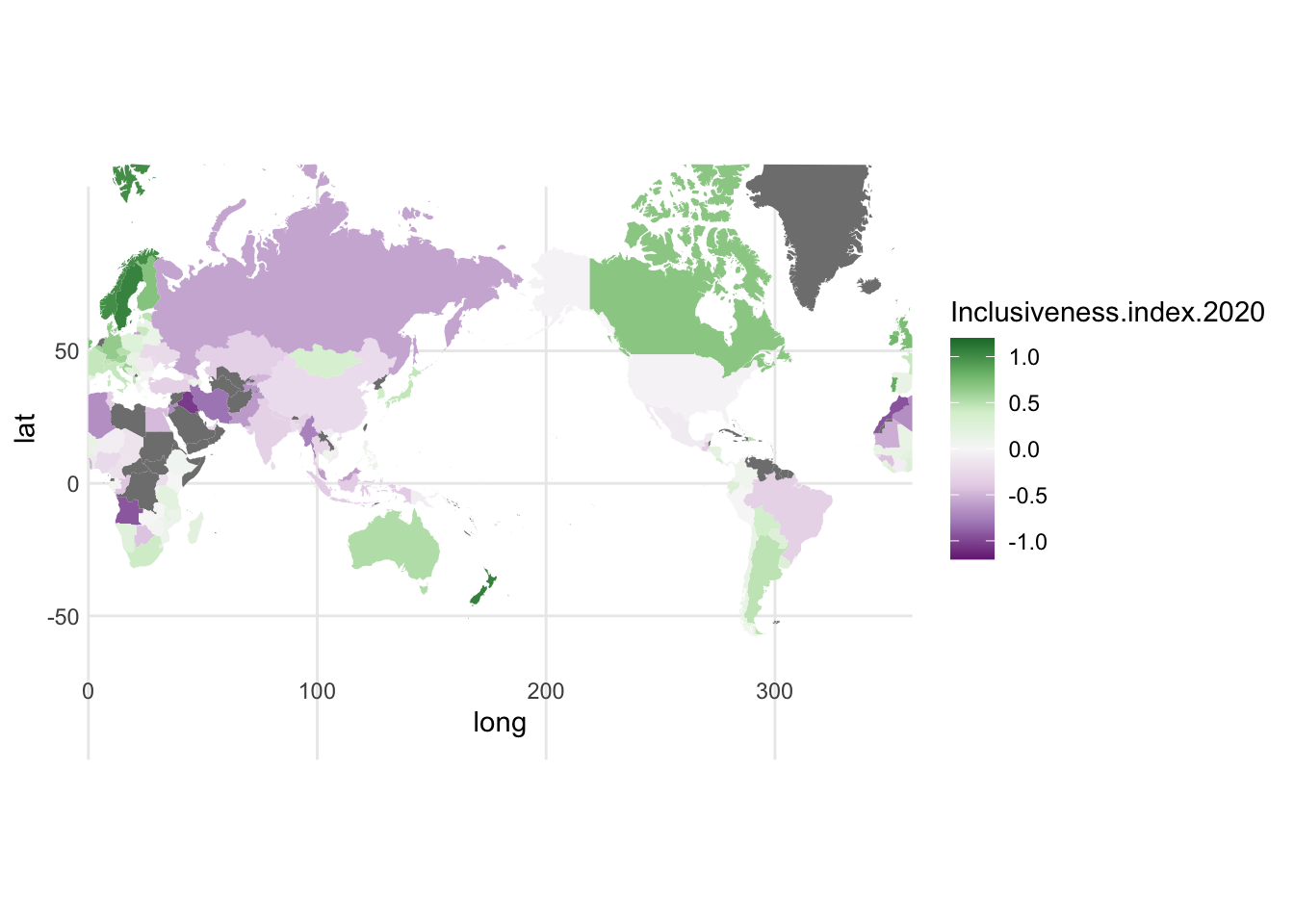
1.8.1 Choropleth
- data visualized is really just the name of the country or other location, and either one categorical variable or one numerical variable.
- Reading these is tricky, because you sort of have to ignore the size of the country. big countries can have low data values, and small countries can have high values. also, if you look across the map and see a lot of one color, that could be many countries or just one big one.
- true of any map: if the data do not have a strongly spacial pattern, displaying the data on a map may just look like a splatter painting
- one benefit, however, is that each country stays within its boundaries; the data never overlap
- also, country shape can be recognizeable and help people make sense of some of the specific patterns in the data
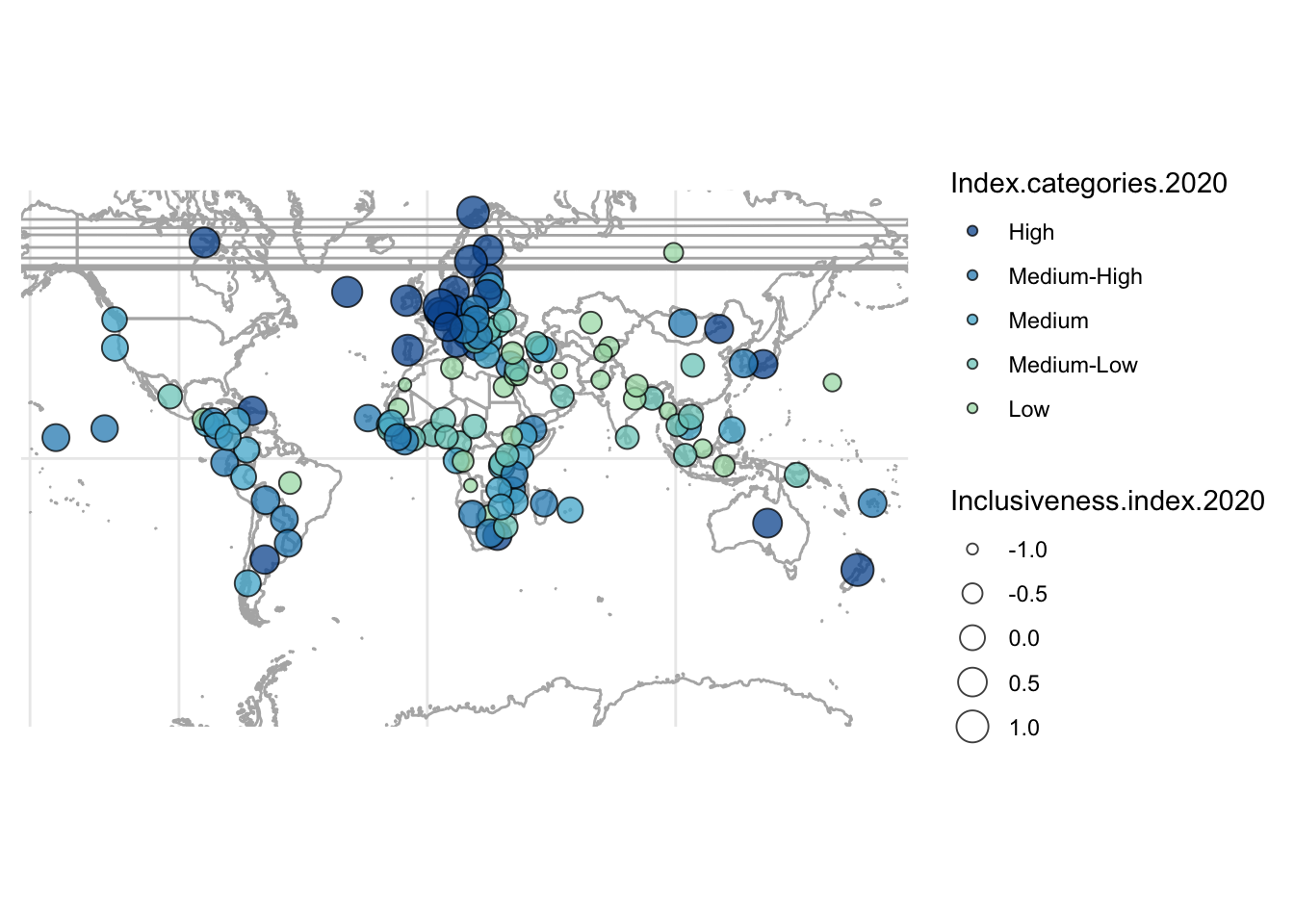
1.8.2 Proportional Symbol Map
- instead of using country boundaries as the shape for the visualizations, those can be used just to locate the data, and the visualization can actually use a different shape. most common shape is a circle, turning the map into a scatter plot or bubble chart.
- bubble charts can use both color and size to display data, so that makes this kind of map a bit more powerful than a choropleth
- but, can get a lot of overlap, can be hard to associate a bubble with a country